Return to GeoComputation 99 Index
This research develops a method to identify local areas where a model has performed well when predicting some spatial distribution.
There is increasing interest in the use of non-spatial tools such as expert systems and artificial neural networks for mapping continuous or fuzzy spatial properties. This is because they can deal with more ancillary variables than spatial interpolation techniques such as co-kriging. Non-spatial tools do not provide truly spatial error measures so it is important to assess their spatial performance in order to identify local areas of acceptable prediction. These areas may then be utilised with confidence. Areas where there is not acceptable prediction may indicate the need for other variables in the model, or a different approach.
The method uses a variant of Geographically Weighted Regression (GWR; Brunsdon et al, 1996). Measured values are compared with predicted values within circles of increasing size to allow the visualisation of error at increasing scales. No spatial weighting scheme is used. GWR is used because it allows the calculation of error values without transforming the original values to error residuals, and over locations where there is no measured data. The error is the square root of the area between the optimal 1:1 line and a fitted line, bounded by the maximum and minimum predicted values. The r2 value indicates confidence in the assessment and is used to determine the best spatial scale.
The method is demonstrated using results from an artificial neural network trained to infer aluminium oxide percentage across an 1,100 km2 area in Weipa, far north Queensland, Australia.
There is increasing interest in the use of non-spatial methods such as expert systems and artificial neural networks to map continuous or fuzzy spatial properties (Foody 1996a, b, 1997; Foody et al, 1997; Gessler et al, 1996; Zhu et al 1996, 1997). These methods are usually assessed using non-spatial, global error assessments and are reported as statistics or error matrices. This research presents a method of detecting areas of acceptable prediction in the results of such models.
A global accuracy assessment indicates how reliable model results are but, like any global statistic calculated from spatial data, global accuracy assessments summarise the error from many locations. Some parts of a study area will be better predicted than others. While accuracy may be mapped into geographic space, ground truth locations are normally sampled as points. This makes it difficult to identify where there are clusters of acceptable prediction. It is therefore useful to conduct some form of spatial error analysis to detect these clusters. Such areas may then be utilised with confidence. Areas where there is not an acceptable level of prediction may indicate the need for other variables, or a different approach. Isolated locations of acceptable prediction may be considered accidentally predicted. While they conform sufficiently to the trained model to be correct, none of the surrounding areas do.
A method that spatially analyses model error should be able to:
The analysis of continuous error is normally done by assessing the residual differences between the measured and predicted values. Positive residuals are errors of commission and negative residuals are errors of omission.
A simple method of spatially visualising residual errors is to use large point symbols, however this is not amenable to multi-scale interpretation as it is greatly affected by the spatial density of the measured data points. Visualisation in this way also does not generate an index of spatial error.
A simple multi-scale approach is to calculate the mean, standard deviation and range for each cell over increasing spatial lags. Areas of acceptable prediction will have a mean residual of zero, a small standard deviation and a small range. However, this approach is sensitive to extreme values and can be difficult to interpret as there are three continuous data attributes. The spatial error residual may be assessed using co-variograms (Goovaerts, 1994). However, while this enables some indication of the spatial structure, it uses a global model of correlation and requires interpretation by the user. It is thus difficult to adapt to the spatial assessment of error at hundreds to thousands of points.
Residual errors may be assessed spatially for local areas in two ways. The first measures the spatial association of the residuals, while the second directly calculates the spatial error residual from the measured and predicted data.
Local spatial autocorrelation indices (Anselin, 1995) provide an obvious method for spatially assessing residual errors. They provide indices of spatial association that are easy to interpret and not too sensitive to extreme values. The general model of a local spatial autocorrelation index is the local spatial co-variance divided by the global variance. Direct calculation of the spatial error residual is possible using a variation of Geographically Weighted Regression (GWR; Brunsdon et al, 1996).
Spatial autocorrelation statistics may be used to identify hot-spots in data sets without being too sensitive to the spatial density of data points. They can identify areas of low and high error and also the magnitude of omission and commission errors. Several of these statistics will calculate values for locations where there is no measured data, for example Gi* (Getis and Ord, 1992, 1996; Ord and Getis, 1995) and the Geographical Analysis Machine (GAM; Openshaw, 1998). Spatial error analysis using global spatial autocorrelation statistics has been attempted previously by Henebry (1995), although only total error was analysed.
However, univariate spatial autocorrelation statistics cannot give an indication of the magnitude of errors of omission, commission and total error using the one assessment (one run of a program). This is because they deal with values in a way that makes omission and commission errors mutually exclusive.
Indices such as Gi* and GAM identify clustered autocorrelated values that are significantly different from the global mean. The residual error mean will be close to zero, so to discover clustered values of low error requires that the values be inverted around zero. This is so values close to zero become large and thus identifiable as hot spots. This requires back-transformation to interpret the results in the same units as the original values, unnecessarily complicating the analysis.
The mix of positive and negative residuals leads to further complications when analysing omission and commission errors. Values of -1 and +1 have the same total error magnitude but are treated as very different by spatial statistics. One approach to analysing positive and negative values is to add the minimum value so they are positive. However, it is difficult to back-transform such data after autocorrelation analysis to identify areas of omission and commission error. This is particularly the case if the residual mean is not zero. Further problems arise when errors of omission and commission are assessed. Positive and negative residuals of the same magnitude must be analysed in isolation of each other. The errors of omission (or commission) may be excluded completely, although this method halves the number of available values and reduces the area over which it is possible to assess the error. Alternately the excluded values may be set to zero, although if this is done then the mean and variance must be adjusted.
Total error may be dealt with by taking the absolute value of the residual, but the mean will not always be zero, particularly where the classification is very biased towards omission or commission. This makes the interpretation of spatial autocorrelation statistics difficult unless they are forced to use zero as the mean.
Confidence values also cannot be generated using spatial autocorrelation statistics, although tests for correlation are possible (Ord and Getis, 1996).
In summary, univariate spatial autocorrelation indices are not appropriate, as they satisfy only the second requirement for the spatial analysis of error.
GWR (Fotheringham et al, 1996, 1997a, b; Brunsdon et al, 1996) is a multivariate approach to analysing spatial data that calculates local regression parameters for a geographic window moving across a dataset. This enables meaningful analysis in the presence of non-stationarity.
GWR can directly assess error residuals using measured and predicted values. There is no need for transformation and back-transformation of values. GWR also allows the simultaneous measurement of total, omission and commission error. It can calculate residuals for locations where there is no measured data and provides confidence information using the r2 goodness of fit statistic. As with all spatial analyses, GWR statistics may be calculated for increasing spatial lags to identify areas of similar prediction at different scales.
This approach uses Ordinary Least Squares (OLS) regression (Equation 1). The spatial error value is related to the deviation of the fitted line from the optimal line, which has a 1:1 relationship and parameters a=0 and b=1. Optimal prediction is achieved when the predicted values exactly match the measured values. It is possible to use higher order polynomial regression but this has not been implemented here.
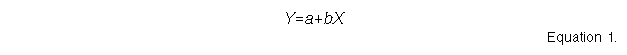
where Y is the variable being predicted given variable X, a is the intercept, b is the slope of the relationship.The published version of GWR attempts to optimise the spatial weighting function to each point in a dataset (Fotheringham et al, 1997b; Brunsdon et al, 1998). This is done by cross validation excluding the central point to optimise the spatial decay parameter for each location. Such an approach is inappropriate for error assessment in a raster data structure. First, it requires data at every point to optimise the spatial weights matrix. Second, it forces an assumed spatial structure on the data, one that decays with a power of distance. This does not allow easy interpretation. A better approach uses circles of increasing radius, similar to spatial autocorrelation statistics. These may be centred on any location without the need to optimise a spatial weights matrix. The best scale for each cell may be determined using the maximum r2 value over all scales.
The deviation of the fitted line from the optimal line may be used to indicate the error magnitude. This may be calculated using the intercept of the two lines and the distribution of the predicted values (Figure 1). The intercept occurs when X=Y, and is calculated for the fitted line using Equation 2. The interpretation of the error changes whether b is positive or negative (Table 1, Figure 1).
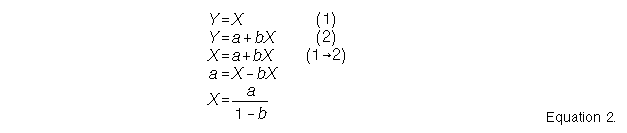
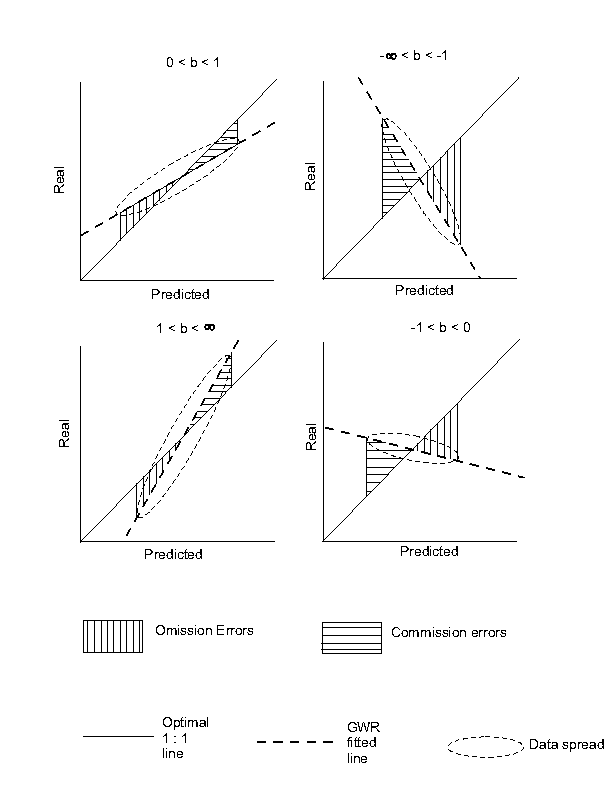
Figure 1. The effect of the slope of b on the the type of error.
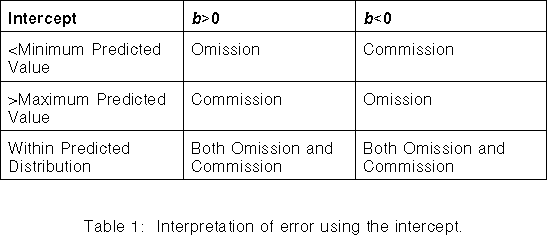
Table 1 and Figure 1 show the interpretation of error is simple when the intercept falls outside the predicted distribution, as the error is either all omission or all commission. When the intercept is within the predicted distribution the error is a mixture of omission and commission. The magnitude of each type of error may be measured by the square root of the area between the fitted and optimal lines bounded by the predicted distribution. The area is used because it is less affected by small data samples than by summing the errors of only measured locations. The predicted maximum and minimum values are used as bounds because the distance from the intercept to the predicted values increases as b approaches 1. This generates large areas between the lines and gives a false indication of large error.
The behaviour of the bounded area between the fitted and optimal lines conforms to the interpretation of the regression line for error. As the fitted line becomes vertical (b approaches +/-infinity) there is a decreasing relationship between the predicted and measured data and the bounded area will increase towards infinity. When the fitted line becomes horizontal (b approaches 0) there is also no relationship among the data, the best measure is the mean of the measured data. The area will also be much greater for negative slopes because of the inverted association.
The r2 is a measure of the goodness of fit of the fitted line to the predicted data. Low r2 values indicate low confidence caused by dispersed data values. Areas with high r2 values have reliable b parameters and therefore reliable error measures. Areas with low r2 values should be ignored, as the value of b is meaningless. The use of r2 should allow the exclusion of areas where extreme values will cause unrealistic error values. The best spatial scale is where the r2 is highest.
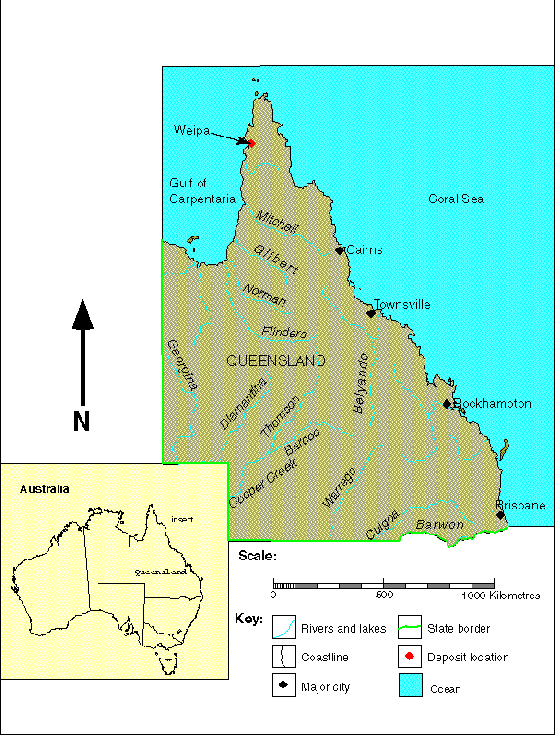
Figure 2. Location Diagram.
The dataset consists of aluminium oxide percentages for 14833 drill cores, a digital elevation model (DEM) interpolated from 5m elevation contour data using a drainage enforcement algorithm (Hutchinson, 1989), and a Landsat Thematic Mapper (TM) 5 image. The aluminium oxide percentages have been provided by Comalco Aluminium Limited and multiplied by a constant value for confidentiality. A cellsize of 30m has been used to maintain consistency with the Landsat data.
A feedforward neural network was trained using backpropagation to infer aluminium oxide percentage. The independent variables used were TM bands 2, 4 and 7, elevation, slope (Zevenbergen & Thorne, 1987), flow accumulation (fD8 algorithm; Gallant & Wilson, 1996), distance from streams, and distance from ponds. Samples that did not encounter bauxite, and samples from areas visible as already mined or as rehabilitation, were excluded from the analysis. The best network training run used eight hidden nodes and had a mean squared error of 0.03264.
A subset of the output classification is presented in Figure 3. The classification is 30.4% correct within +/-1 original units and 48.72% correct within +/-2 original units.
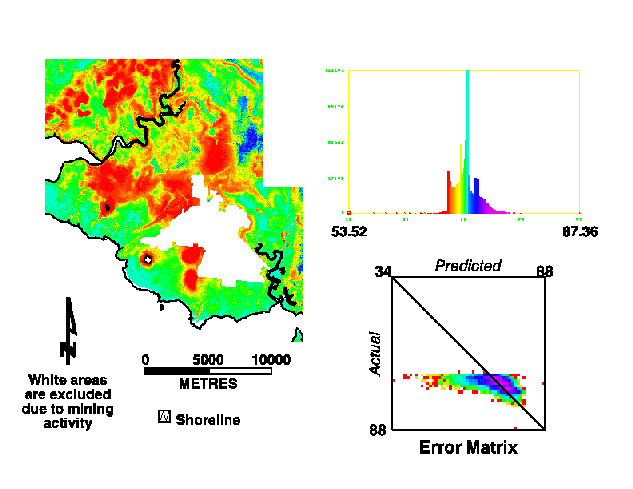
Figure 3. Neural Network continuous classification with error matrix (red = low count, magenta = high count).
The GWR analysis has been implemented in Arc/Info GRID using Arc Macro Language (AML) scripts. The method was applied to a subset of the aluminium oxide classification using spatial lags from three cell units out to ten cell units, with distance increments of one cell unit. A minimum of five points was required to calculate regression parameters.
Example results for individual spatial lags are shown in Figure 4. The total, omission and commission errors for the maximum r2 value for each cell are shown in Figure 6. The maxmium r2 and spatial lag are shown in Figure 6.
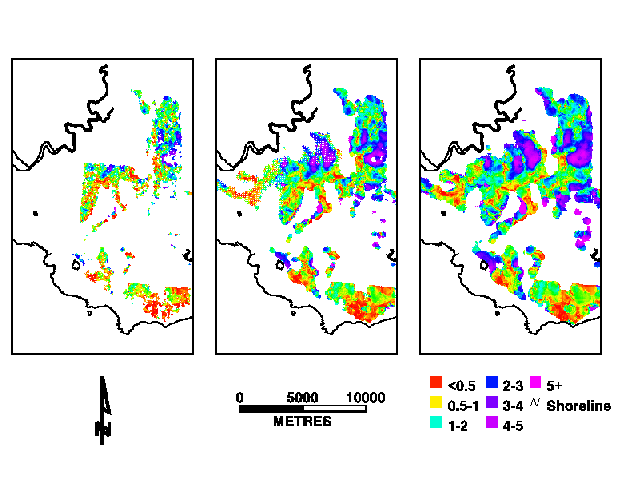
Figure 4. Example errors for spatial lags with 4, 7 and 10 cell radii. The spatial distribution reflects the density of the measured data.
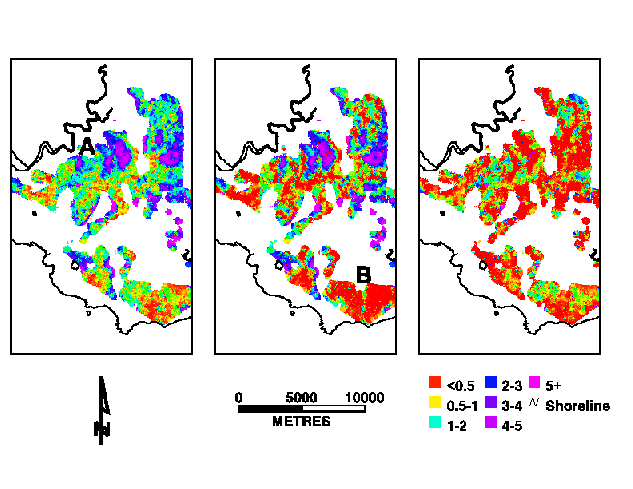
Figure 5. Total, omission and commission errors for maximum spatial r2.
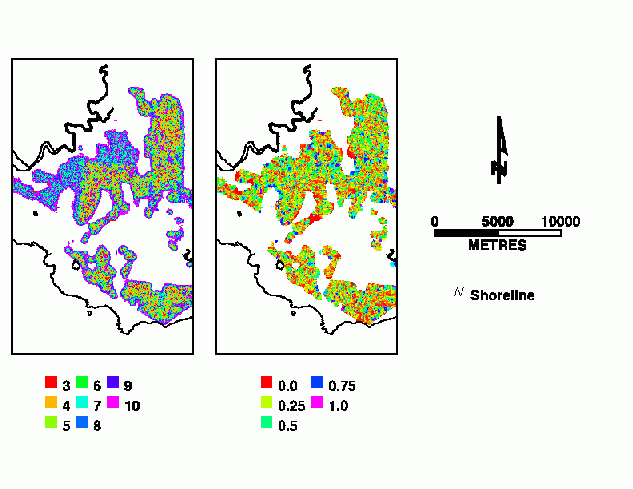
Figure 6. Optimal spatial lag and maximum r2 value.
Visualisation of the omission and commission errors with the r2 values may be done using simple remote sensing methods. A red/green/blue false colour image is shown in Figure 7, with r2 as red, omission errors as green and commission errors as blue. Areas of low error with high confidence are coloured red, high error with high confidence is coloured white.

Figure 7. RGB image of r2 and omission and commission errors
There are extensive areas where commission is low but fewer areas where omission is low. Even though the total error is the sum of the omission and commission errors there are also extensive areas where the model appears to have performed well. Figure 8 shows large areas where the total spatial error is less than one original unit. However, when an r2 threshold of greater than 0.5 is used the area reduces into non-contiguous groups.
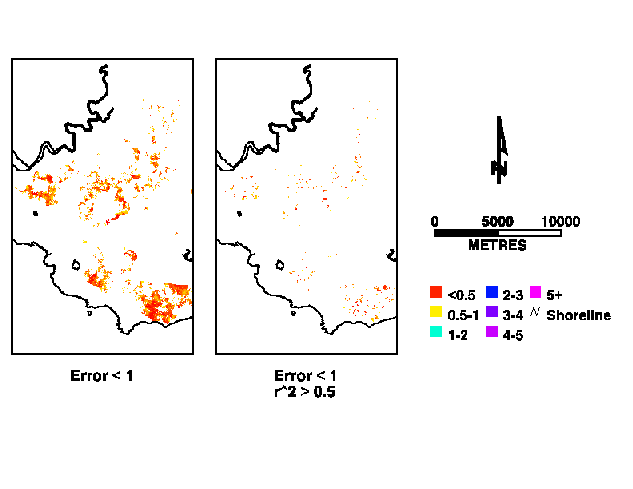
Fig 8. Areas where total spatial error is less than 1 and where the r2 is greater than 0.5.
An example of where the model has a high error is the arcuate featuresin the northern part of the sub area (Figure 5, location A. These features have high errors of omission only, except their crests which have only errors of commission. These features are associated with arcuate ridges and are an area that requires further investigation.
An area in the south of the subset shows a large cluster with very low error (Figure 5, location B). However, most cells have an r2 below 0.5 and are thus unlikely to be good estimates. This is fortunate because the sample points are interspersed with many other samples that did not encounter bauxite.
The results appear not to be affected by sample density, although there are definite edge effects where it was possible to calculate only the higher spatial lags. These are best shown where they overlap the mining mask. The analysis shows low spatial error but the data used are some distance from the central point. Edge and other sampling effects may be reduced by using ancillary layers as masks.
The contiguous areas of similar spatial error may be interpreted as areas where the ANN model could be improved. This might be through extra independent variables, or by separate analysis. The randomly distributed areas may be considered areas where a different approach should be tried.
Data outliers affect all spatial autocorrelation statistics. For error assessment there should be a limit to the number of values treated as outliers and excluded from the analysis. This is because the correlations are expected to decrease as the lag is increased, extreme values are thus not necessarily outliers. Possibly a subjective threshold may be imposed to regulate the exclusion of possible outliers based on the quantity and value of those data points. Another approach is to weight the values by their distance from the regression line, with distant values receiving less weight. This has been proposed by Fotheringham et al (1996). The danger of this is that the spatial error relationship will become biased towards artificially low error values.
Outliers often occur because the sampling scheme is inappropriate to the phenomenon being analysed. Given a sampling scheme that is appropriate to the process, true spatial outliers should be excluded from the analysis. They should then become a problem of the least squares fitting. Using circles of increasing size will approximate most shapes to a reasonable degree without needing to explore the data for an ideal, and possibly adaptive, shape. Higher spatial error values indicate it is probably beneficial to use such sampling schemes in the original modelling.
Another problem of outliers is that they will cause low r2 values, from which many error estimates will be rejected. Some investigation of this needs to be undertaken before further application of the method.
The regression parameters may also be used to correct the model predictions. It must be decided whether there is any extra benefit in post processing the results of a non-spatial model using many ancillary variables. In the case of this analysis the results are a slight improvement on universal kriging (implemented in Arc/Info; Figure 9). This might be considered a direct result of including spatial processes in the ANN model.
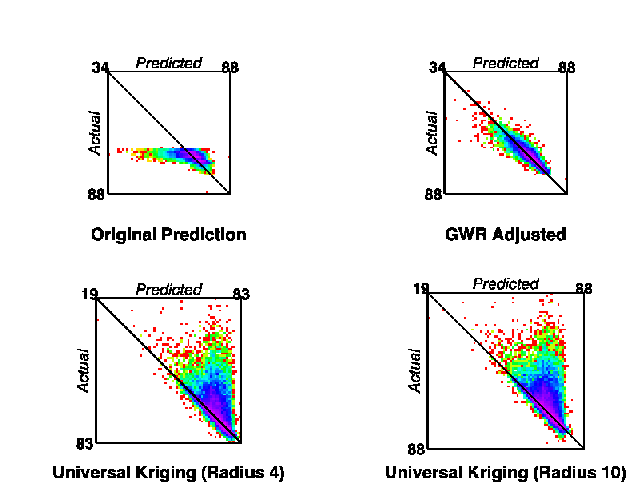
Figure 9. Error matrices for original neural network prediction, GWR adjusted and universal kriging with 4 and 10 cell radii.
The method is currently exploratory and gives a good indication of the extent of the model errors. However, the extension of the results to resource evaluation requires tests for significance at each location to determine if the r2 is meaningful. This has not been implemented here but is a direction for future work.
GWR, with some modifications, allows the investigation of non-spatial model results to identify the spatial distribution of the model error. Acceptable model results will have low error values over large, contiguous areas. Unacceptable results will have small, near randomly distributed areas of acceptable prediction or large, contiguous areas of high error.
GWR is useful because it can summarise total, omission and commission errors using only one assessment by directly comparing measured with predicted values for all locations in a dataset. It can calculate the spatial error for all locations in a dataset, provided they have measured values within the sampling window. Confidence in the assessment is provided by the r2 value. GWR makes the interpretation of the error much easier than univariate spatial autocorrelation statistics.
GWR has been shown to work using a spatially dense dataset, indicating several areas of acceptable and unacceptable model prediction. Many of these were not immediately obvious when looking at the point data.
The method is currently exploratory and tests for significance need to be implemented before the results are applied to resource evaluation.
Anselin, L, 1995; Local indicators of spatial association - LISA, Geographical Analysis, 27 (2), 93-115.
Brunsdon, C., Fotheringham, A.S. & Charlton, M.E., 1996; Geographically weighted regression - a method for exploring spatial nonstationarity, Geographical Analysis, 28 (4), 281-298.
Brunsdon, C., Fotheringham, A.S. & Charlton, M.E., 1998; Spatial nonstationarity and autoregressive models, Environment and Planning A, 30 (6), 957-973.
Foody, G.M., 1996a; Relating the land-cover composition of mixed pixels to artificial neural network classification output, Photogrammetric Engineering and Remote Sensing, 62 (5), 491-499.
Foody, G.M., 1996b; Fuzzy modelling of vegetation from remotely sensed imagery, Ecological Modelling, 85, 3-12.
Foody, G.M., 1997; Fully fuzzy supervised classification of land cover from remotely sensed imagery with an artificial neural network, Neural Computing & Applications, 5 (4), 238-247.
Foody, G.M., Lucas, R.M., Curran, P.J. & Honzak, M., 1997; Non-linear mixture modelling without end-members using an artificial neural network, International Journal of Remote Sensing, 18 (4), 937-953.
Fotheringham, A.S., Charlton, M. & Brunsdon, C., 1996; The geography of parameter space - an investigation of spatial non-stationarity, International Journal of Geographical Information Systems, 10(5), 605-627.
Fotheringham, A.S., Charlton, M. & Brunsdon, C., 1997a; Measuring spatial variations in relationships with geographically weighted regression, in Fischer, M.M. & Getis, A. (eds), 1997, pp 60-82.
Fotheringham, A.S., Charlton, M. & Brunsdon, C., 1997b; Two techniques for exploring non-stationarity in geographical data, Geographical Systems, 4, 59-82.
Gallant, J.C. & Wilson, J.P., 1996; TAPES-G - a grid-based terrain analysis program for the environmental sciences, Computers and Geosciences, 22 (7), 713-722.
Gessler, P., McKenzie, N. & Hutchinson, M.F., 1996; Progress in soil-landscape modelling and spatial prediction of soil attributes for environmental models, Third International Conference/Workshop on Integrating GIS and Environmental Modelling, Santa Fe, New Mexico, January, 1996. http://www.ncgia.ucsb.edu/conf/SANTA_FE_CD-ROM/sf_papers/main.html.
Getis, A. & Ord, J.K., 1992; The analysis of spatial association by use of distance statistics, Geographical Analysis, 24 (3), 189-206.
Getis, A. & Ord, J.K., 1996; Local spatial statistics: an overview, pp 261-277 in Longley, P. & Batty, M., (eds); Spatial Analysis: Modelling in a GIS Environment, Geoinformation International, Cambridge.
Goovaerts, P., 1994; Study of spatial relationships between two sets of variables using multivariate geostatistics, Geoderma, 62, 93-107.
Hutchinson, M.F., 1989; A new procedure for gridding elevation and streamline data with automatic removal of spurious pits, Journal of Hydrology, 106, 211-232.
Longley, P.A., Brooks, S.M., McDonnell, R. & MacMillan, B., 1998; Geocomputation: A Primer, Wiley, UK, 278pp.
Openshaw, S., 1998; Building automated geographical analysis and explanation machines, in Longley et al, pp95-115.
Ord, J.K. & Getis, A., 1995; Local spatial autocorrelation statistics: Distributional issues and an application, Geographical Analysis, 27 (4), 286-306.
Schaap, A.D., 1990; Weipa kaolin and bauxite deposits, in Hughes, F.E. (ed), Mineral deposits of Australia and Papua New Guinea, 1669-1673, The Australasian Institute of Mining and Metallurgy, Melbourne, 1828pp.
Zevenbergen, L.W. & Thorne, C.R., 1987; Quantitative analysis of land surface topography, Earth Surface Processes and Landforms, 12, 47-56.
Zhu, A.X., Band, L.E., Dutton, B. & Nimlos, T.J., 1996; Automated soil inference under fuzzy logic, Ecological Modelling, 90 (2), 123-145.
Zhu, A.X., Band, L., Vertessy, R. & Dutton, B., 1997; Derivation of soil properties using a soil land inference model (SOLIM), Soil Science Society of America Journal, 61 (2), 523-533.