Return to GeoComputation 99 Index
Steve Dowers, Bruce Gittings and Mike Mineter
University of Edinburgh, Department of Geography, Drummond Street, Edinburgh, EH8 9XP United Kingdom
E-mail: sd,bruce,mike
In this paper the authors explore the potential for promoting high-performance computing, in particular parallel processing, of geo-spatial data from a specialised area of research to a tool generally available for building scalable information services. This is placed in the context of standards for interoperability.
Over the last few years the handling of spatial information has moved from the domain of highly specialised Geographical Information Systems (GIS) to become one of the key components of broader Information Technology (IT). This has come about both at the organisational level, where GIS have been integrated into the corporate IT functions, and at the technical level, where modern data models integrate both spatial and attribute data into standard dbms technology, rather than relying on proprietary hybrid models that invoke customised code to handle the spatial component. An increasing number of organisations have realised the value of spatial data in their normal operations, along with the increased availability of packages to manipulate spatial data and the range of off-the-shelf data. In many cases this will have been a gradual process with small applications raising awareness of the wider benefits to the organisation. Increasing use and the spread of applications then raises the issue of managing the data and making sure that it is used cost-effectively. To address these issues, most of the major database vendors have now included support for spatial data in their products by providing a framework for storing the data in tables within the database, for creating spatial indexes on these tables, and by extensions to the query language to support spatial predicates and functions. In some cases these features are implemented using object-oriented (O-O) extensions to the traditional relation database technology, or indeed making use of fully O-O systems, based on an underlying oodbms or object-store. The storage and retrieval of spatial data is therefore well placed to exploit parallel processing architectures since database vendors are now supporting multiprocessor architectures with shared and distributed memory (MIMD-SM and MIMD-DM). The actual implementation of the database is largely transparent to the end user, allowing the database service to scale as use increases. The prevalence of the client-server architecture in database applications, distributed databases, location transparency, and name services, support this flexibility in building scalable applications.
One of the factors that has facilitated this development in databases is the creation of standards for aspects such as the query language (i.e., SQL) and remote database access; however, the development of similar applications using spatial data has been inhibited by the lack of standards covering the storage (tables structure and datatype), processing and interoperability. The use of parallel processing in GIS and remote-sensing has been considered a very specialised area due to the complexity of developing parallel algorithms, the range of data structures used, and difficulty in integrating the resulting software with monolithic commercial packages, usually based on proprietary data models and storage formats.
Much of the early work in relation to standards has been focussed towards spatial data exchange. Yet, while there are a wide range of local and national standards for spatial data exchange, there have been no globally accepted standards. Clearly standards would be beneficial at other levels, and this lack was recognised at the start of the 1990’s with initiatives to standardise extensions to SQL to support a range of multi-media data including spatial, text, audio, and video. At about the same time the issue of interoperable geo-processing began to be addressed in earnest, leading to the incorporation of the Open GIS Consortium in 1994. The development of standards generally is a detailed and painstaking process with the results that the SQL3 standard, where development started in 1992, is only now approaching publication. The work undertaken by the OGC has resulted in a general awareness of the need for, and advantages of, interoperability, and in a significant body of documents covering the requirements for geo-processing, the abstract specification model, and a detailed examination of components of the OpenGIS Specification Model in 14 topic volumes (Buhler, McKee, 1998; OpenGIS Consortium, 1998). A great deal of work remains to be done on some of the topics but the core technology is partly in place.
Through the implementation of these standards, the components of the GIS become 'plug-and-play', and thus new components can easily be plugged into existing systems through a fully defined standard interface. These new components may include specialist modules to handle, for example, spatial statistics or perhaps environmental models, which are not appropriate as part of a generic GIS. We would further suggest that this model should be used to permit the replacement of selected slow serial algorithms (relating to particularly intensive operations, for example, polygon overlay) with alternative parallel algorithms. Thus, the way is now clear to remove one of the obstacles in making parallel geo-processing available to the end user.
Although there is now a body of literature on interoperability of GIS in general, and in environmental modelling in particular, much of the research has taken place in exploring functionality, and there has been less emphasis placed on performance and scalability. Karami (1997) has explored the provision of high performance computing as part of a distributed architecture for tightly coupling environmental modelling with GIS. Vckovski (1998), describes the main problems to be faced in interoperable GIS and examines the particular issues of fields and uncertainty in this context. He proposes a model for a virtual data set, which encapsulates both data, and methods for understanding the data. Using an experimental design based on Java, he shows how this approach provides a model where either or both of data and methods can travel between client and server to support a variety of implementation modes. While this type of approach provides a very flexible method for concealing the data storage from the data user, but there are component operations where the requirement for high performance means that this method of access is inappropriate. In these situations, the operation may require access to the data as collections of the stored representation, rather than access to individual features, or derivations of them; therefore, the interface to data needs to be sufficiently general to support both the virtual data set concept of Vckovski, for access to individual features, and also the requirements for high-performance access to the data, however that may be defined. As experience with the GeoLens prototype has shown (Behrens et al., 1997), the OpenGIS Specification does not cover the data model and representation for transfer to the client, which is a particular problem for large collections of features or large subsets of coverages. This is because the high latency, which is characteristic of connections over the Internet, make the invocation of individual operations at the feature or object level relatively inefficient. The Open Geospatial Datastore Interface (OGDI) (Morin et al., 1997) is an example of current developments to provide transparent access to data stored in a variety of formats.
Topic 12 of the Open GIS Abstract Specification explores the range of services needed to support geo-processing and how these relate to services for other application areas. These are set in the context of other standards, such as platform services defined by IEEE P1003.0 and Common Object Request Broker Architecture (CORBA) from the Object Management Group. The approach is based on distributed computing and object-orientation, but also can embrace non-OO technology such as Distributed Computing Environment (DCE). It also provides a framework for integrating ‘legacy’ components by using wrappers and defining the interface to them using Interface Definition Language (IDL). The framework is applicable to a range of scales from embedded systems, through desktop systems, to enterprise-wide information servers. From the geo-computation perspective, the locational transparency and object broker facilities of the service architecture will allow parallel algorithms to be implemented, and published in a manner that is transparent to client applications. The pluggable component approach will allow services that present performance problems to be turbo-charged to create a balanced set of services without bottlenecks.
In some server applications, such as Intranet or Internet web servers, parallel components will allow additional opportunities to scale performance to match increases in demand. The distributed computing model provides scope for scaling to match increases in the number of requests, as do shared memory parallel architectures (MIMD-SM). Reducing the response time for individual requests can only be effectively addressed by parallel processing.
There is an analogy here with the application of parallel architectures to relational database management systems. In the first commercial implementations of parallel dbms, the aim was towards improving transaction processing performance, hence the concentration on locking and similar issues; however, it was the development of parallel processing of single queries that led to true scalability of performance, and then the appearance of data warehousing necessitated the efficient querying of massive amounts of data.
To allow parallel components to plug into a service framework there must be a common understanding of the data models by which abstractions of the real world are represented, and of the ways in which data are exchanged between components. Many of the issues yet to be resolved relate to semantics arising from the way different information communities visualise and model the real world (Worboys and Deen, 1991). From the technical viewpoint we are not concerned with these issues; however, we are concerned with how a parallel component retrieves, or is passed, inputs and parameters and with how the results are provided to the consumer. This includes an understanding of the way in which data access services are provided.
Drawing on examples from the OpenGIS Service Architecture, there are several service areas in which parallel can offer scope for truly scalable implementations:
While many systems will not require parallel processing in many of these areas, multiuser real-time systems, such as web-based decision support systems, would gain substantial benefits. There also is a large range of application-specific modules, such as environmental process models. While not specifically identified in the abstract specification, such models can be considered as additional services in the framework allowing an environmental application to take advantage of other services and tools.
Despite the range of operations in the list above, they often can be characterised by the type of data that is processed. We can identify 3 broad categories:
While these categories can be simplified into the two classes of object-based and field-based models, we have separately identified the models relating to terrain due to their prevalence, and since the field of terrain modelling has been the subject of considerable research in parallel algorithms (see Magillo, Puppo, 1998).
Some operations operate entirely in one of these categories, while others operate as conversion operations or in combining different types. From the perspective of implementing a parallel operation, the type of data, the corresponding data model, and its representation are important factors in determining a parallelisation strategy. In the context of the OpenGIS service environment, this may be complicated by the nature of the interface to the Geospatial Information and Retrieval Services
Previous work by the authors (Mineter and Dowers, in press) and others has explored the common ground across a range of parallel applications and strategies. The benefits of one or more layers of software library, which encapsulate some of the complexity of adapting an existing sequential algorithm for parallel implementation, have been demonstrated. These software layers conveniently hide many of the issues, such as communication and synchronisation. In the context of this paper, these layers also may encapsulate the interface to the service architecture and provide a framework for exposing an appropriate interface to the object-oriented world outside, even if the algorithm does not adopt the object-oriented paradigm itself.
Healey et al., (1998) describes some of the approaches adopted by the authors in designing a framework for implementing parallel algorithms that involve vector geometry, concentrating on areal data with topology, and/or raster data. An overall goal was the design of generic approaches that were portable across parallel architectures and applicable to a range of spatial operations. The portability issue was largely addressed by the use of standards for communication between processes and the development of software libraries building on these standards to provide generic facilities. The research had been undertaken as part of a larger programme; therefore, development of the software libraries was considered a product in its own right. The basic design was originally carried out using a message passing library developed at the Edinburgh Parallel Computing Centre (EPCC) called the Common High-level Interface for Message Passing (or CHIMP). This has been changed to use the MPI standard (MPI Forum, 1993), which is available for both MIMD-DM and MIMD-SM environments. The result was a Parallel Utilities Libraries (PUL) (Bruce et al., 1995) which included PUL-PF for parallel file access and PUL-GF for global shared file access, both of which are described in Trewin (1998).
The parallelisation strategy in each case involves spatial decomposition into either strips or blocks (see Figure 1). The framework identifies the following 7 modules (Figure 2) which are largely independent of one another:
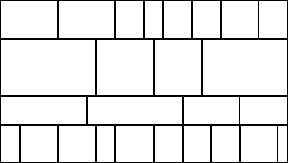
Figure 1: Strip-block decomposition
In those cases where the processing is purely in the raster domain, there are alternative libraries, such as PUL-RD (regular-domain decomposition) (Chapple et al., 1995) which support spatial decomposition by sub-blocks including halos (overlaps between blocks) and halo exchange during processing. Traditional task farm approaches also may be applied.
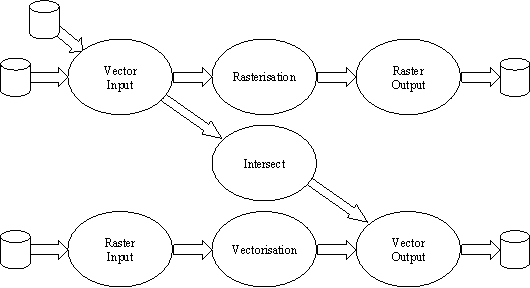
Figure 2: Modules for parallel GIS operations
While the raster input and output modules use a simple run-length encoding scheme suited to classified images, they could equally use other formats such as band-sequential by row or column. The data model for grid and raster data proposed in Topic 1 of the OpenGIS model does not prescribe a particular approach but identifies band-sequential, band-interleaved, and Morton ordering. Other standards such as DIGEST (DGIWG, 1994), specify a run-length encoding within sub-blocks. A block oriented run-length encoding scheme could prove of benefit in the raster input module if the complexity of a block, and therefore an estimate of the amount of processing it, is available as part of the meta-data held with an image. The sequencing of blocks has considerable implications for the performance of the phase that stitches geometry and topology together across blocks during raster to vector conversion. In these designs, the blocks are organised sequentially across the image extent in strips, which allows the stitching component to build domains that grow as the processing of the image proceeds.
The British Standards Institution (BSi) standard NTF Level 4 transfer format was chosen for vector data since it was considered a vendor-neutral format (British Standards Institution, 1992), although it clearly intended as a transfer standard and not appropriate for production use.
Since NTF adopts a rather disaggregated model with several records required to represent the geometry and the topology (Figure 3), the vector input module is designed to bring together the information needed by the algorithm, collected from the various record types in the input stream. The distribution component is designed to present data, sorted in one dimension, to support algorithms that adopt a sweep approach to processing. We chose polygon overlay using a plane sweep (Harding et al., 1998; Preparata and Shamos, 1985) and vector to raster conversion using a scan-line algorithm (Sloan, 1998; Jordan and Barret 1973) as example operations requiring this type of input. A scan-line oriented algorithm was chosen for the raster to vector conversion (Mineter, 1998; Capson, 1984). Since this algorithm also processes scan-lines in a sequence comparable to a plane sweep, a common output library can be used for both polygon overlay and raster to vector operations. A change in data model and representation will obviously have implications for the vector input and output modules.
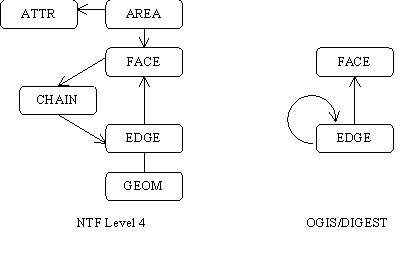
Figure 3: BSi NTF Level 4 and OpenGIS/DIGEST - Area Features
The vector input module implements several sort operations followed by a join, and then a distribution to the worker processes. Because of the redundancy in the NTF model, the chain records are ignored since the left/right encoding on the edge record is sufficient. The sort/join operation linking edges and nodes is therefore redundant for OpenGIS. Since the transfer format itself is not defined, the manner in which attributes are transferred is not defined. For the purposes of a polygon overlay operation it may be sufficient to build output polygons with lists of identifiers from the input polygons. In this case no joining of edges to attributes is required. The vector input stage would simplify to splitting edges into monotonic segments and sorting for distribution to worker processes. Further simplification may be possible if the data source supports spatial queries, particularly if the meta-data includes information on the spatial distribution of the data that could be used to drive the domain decomposition.
Vector output requires geometry and topology to be stitched together across the boundaries of the decomposition domains. The parallel library provides functions to build geometry and topology on the fly during sweep processing. While these are oriented towards the NTF model, it is felt that this paradigm was sufficiently general to support other data models.
The implications for parallel implementation of the data models proposed by the OpenGIS consortium will now be considered. The NTF model separates the geometry information from the edge information describing the topology. The ring information also is held separately in chains. The area information is held in the face and area records with the area record also linked to the attribute records. The various records are linked by record identifiers. The parallel implementation therefore includes support for allocation of unique identifiers for each component. This disaggregation is used to advantage to output the records as and when the information needed becomes available. The records and their dependencies are shown in Table 1. Note that the table records the time when the identifiers are logically known. In practice, the IDs are allocated by a master ID generator process that ensures that unique IDs are generated in sequence. The IDs are therefore not known in the worker process until the message has been received back from the ID generator with the allocated IDs.
Table 1: NTF record ID dependencies
|
Record Type |
Ids in record |
When ID is known |
When record can be output |
|
GEOM |
GEOMID |
At geom creation |
Output when end node is reached |
|
EDGE |
EDGEID |
At edge creation |
Output when both polygons are identified |
|
GEOMID |
At geom creation |
||
|
SNODEID |
At geom creation |
||
|
ENODEID |
At geom completion |
||
|
LFACEID |
At polygon closure |
||
|
RFACEID |
At polygon closure |
||
|
CHAIN |
CHAINID |
At chain creation |
Output when polygon is complete |
|
EDGEID |
At polygon closure |
||
|
FACE |
FACEID |
At polygon closure |
Output when polygon is complete |
|
NODEID |
ZERO |
||
|
CHAINID |
At polygon closure |
||
|
AREA |
AREAID |
At polygon closure |
Output when polygon is complete |
|
FACEID |
At polygon closure |
||
|
ATTRID |
At polygon closure |
||
|
ATTR |
ATTRID |
At polygon closure |
Output when polygon is complete |
The topological feature model proposed in the OpenGIS Specification Model is based on the ‘winged edge’ model used in DIGEST. This effectively aggregates the functions of the GEOM, EDGE and CHAIN into an edge structure. The OpenGIS face simply identifies the FaceID and has no reference to a chain. The OpenGIS model has no long records with lists of chains and edges since the rings that make up the boundary of a polygon are implemented as a linked list. This as a significant implication for a parallel implementation since the edge record cannot be completed until a polygon is closed. The edge records may have to be retained in one or more processes for a potentially long time, including the details for the coordinates. The detrimental effects of this are difficult to estimate and will be data dependent. Strategies to overcome this problem depend on the nature of the interface to the output module, and the overhead involved in using temporary disk or other storage.
We consider 3 scenarios for interface to the data consumer as follows:
In each of these cases the responsibility for managing the output could be handed over to an output server, leaving the worker free to manage the details of the operation. The actual code implementing the algorithm would not be aware of this change since it would be encapsulated in the output library.
It should be noted that the data model used internally in the vector output library is more redundant then either the NTF or OpenGIS models since it explicitly models nodes and the linkage to edges that meet at a node. This is held to allow efficient update of the edge information when the node ID becomes available. The chain information is held internally as a linked list, possibly distributed over several processes. The transition from the NTF model to an OpenGIS model implies no change at the level of the operation since the knowledge of the exact output model and the translation to that is hidden inside a few components of the vector output library.
In this paper the authors have attempted to describe the scope for making the performance of parallel processing available in a transparent manner by building on the principles of interoperability of models such the OpenGIS Abstract Specification Model. By building on existing and emerging standards and libraries we expect the barriers that have limited the uptake of high performance computing to be removed. This comes about through the ability to be able to 'plug' new parallel algorithms into the new generation of OGIS-compliant GIS software. We have shown how research into a generic framework for implementing parallel algorithms can be adapted relatively simply to fit into the OpenGIS service framework and have considered some of the requirements that such an approach might fit for access to spatial data. While the parallel algorithms described are not object-oriented, the OpenGIS framework provides a mechanism for making their services available through packaging and interface specification. Mann (1997) among others has described the need for high-performance services when the computational load becomes too high for local processing. These services may be implemented on a powerful server or may be provided by making use of locally underused resources on workstations or even PCs. The locational transparency of the OpenGIS model means that the user neither knows nor cares unless a cost is involved.
The authors gratefully acknowledge support from the Department of Trade and Industry and the Science and Engineering Research Council during the design stages of this work and from the EPSRC under grant GR/M05751 for implementation work currently under way. We would also like to thank the partners during the design stage: British Gas Plc, Digital Equipment Company Ltd, ESRI-UK Ltd, GIMMS (GIS) Ltd, Laser-Scan Ltd, Meiko Ltd, Oracle Corporation and Smallworld Systems, Ltd.
Behrens, C, L. Shklar, C. Basu, N. Yeager and E. Au, 1997. The Geospatial Interoperability Problem: Lessons Learned from Building the GeoLens Prototype. Proceedings of Interop’97, Santa Barbara, USA, pp.144-162.
British Standards Institution, 1992. Electronic transfer of geographic information (NTF) Part 1. Specification for NTF structures, Bsi, London, U.K., p.46.
British Standards Institution, 1992. Electronic transfer of geographic information (NTF) Part 2. Specification for implementing plain NTF, Bsi, London, U.K., p.72.
Bruce, R.A.A., S. Chapple, N.B. MacDonald, A.S. Trew and S. Trewin, 1995. CHIMP and PUL: Support for portable parallel computing. Future Generation Computer Systems, 11, pp. 211-219.
Buhler, K and L. McKee, 1998. The OpenGIS® Guide, Introduction to Interoperable, Geoprocessing and the OpenGIS Specification, Open GIS Consortium, http://www.opengis.org/techno/specs.htm
Capson, D.W., 1984. An improved for the sequential extraction of boundaries from a raster scan, Computer Vision, Graphics and Image Processing 28, pp. 109-125.
Chapple, S., S. Trewin and L. Clarke, L., 1995. PUL-RD Prototype Users Guide. Technical report EPCC-KTP-PUL-RD-PROT-UG, Edinburgh Parallel Computing Centre, Edinburgh, U.K.
DGIWG, 1994. Digital Geographic Information Exchange Standard (DIGEST), Edition 1.2 ., Military Survey, Feltham, U.K.
Harding, T.J., R.G. Healey, S. Hopkins and S. Dowers, 1998. Vector Polygon Overlay. In Parallel Algorithms for GIS, Healey, R., S. Dowers, B. Gittings, and M. Mineter (Eds.), Taylor and Francis, London, UK, pp. 265-310.
Healey, R., S. Dowers, B. Gittings and M. Mineter, 1998. Parallel Processing Algorithms for GIS, Taylor & Francis, London, U.K., pp. 460.
Jordan, B.W. and R.C. Barret, 1973. A scan conversion algorithm with reduced storage requirements, Communications of the ACM 16(11), pp. 676-682.
Karimi, H, 1997. Interoperable GIS Applications: Tightly Coupling Environmental Models with GISs, Proceedings of Interop’ 97, Santa Barbara, USA, pp. 103-122.
Magillo, P. and E. Puppo, 1998. Algorithms for Parallel Terrain Modelling and Visualisation. In Parallel Algorithms for GIS, Healey, R., S. Dowers, B. Gittings, and M. Mineter, Taylor and Francis, London, pp. 351-386.
Mineter, M.J., 1998. Raster-to-Vector Conversion. In Parallel Algorithms for GIS, Healey, R., S. Dowers, B. Gittings, and M. Mineter, Taylor and Francis, London, U.K., pp. 253-264.
Mineter, M.J. and S. Dowers [In press.]. Parallel Processing for Geographical Applications: A Layered Approach, Geographical Systems.
Morin, P, D., D. Gouin, G. Clément and C. Larouche, 1997. Interoperating Geographical Information Systems using the Open Geospatial Datastore Interface (OGDI), Proceedings of Interop’97, Santa Barbara, U.S., pp.163-180.
MPI Forum, 1993, MPI: A message passing interface. Proceedings of Supercomputing ’93, November 1993, pp. 878-883.
Open GIS Consortium,1998, The OpenGIS Abstract Specification Model, http://www.opengis.org/techno/specs.htm
Preparata, F.P and M.I. Shamos, 1998. Springer-Verlag, New York, NY, U.S., p.398.
Sloan, T., 1998. Vector-to-Raster Conversion. In Parallel Algorithms for GIS, R. Healey, S. Dowers, B. Gittings, and M. Mineter, Taylor and Francis, London, England, pp.233-252.
Trewin, S., 1998. High Level Support for Parallel Programming. In Parallel Algorithms for GIS, Healey, R., S. Dowers, B. Gittings, and M. Mineter, Taylor and Francis, London, England.
Vckovski, A., 1998. Interoperable and Distributed Processing in GIS, Taylor and Francis, London, England.
Worboys, M. and S.M. Deen, 1991. Semantic Heterogeneity in distributed geographical databases, SIGMOD Record, 20(4).