Andreas Bergmann Institute of Computer Science III, University of Bonn, Römerstrasse 164, D-53117 Bonn Germany E-Mail: andreas@informatik.uni-bonn.de
Investigation of global processes like temporal development of ecosystems requires integrated access to the many heterogeneous and distributed sources of Geo data. The object-oriented paleoecological information system OPALIS aims to support interoperability of various data sources. While retaining the advantages of local data maintenance and formats, it will provide uniform access to information by means of integrated queries. In this paper, we present the derivation of Geo domain knowledge out of distributed databases to enable a precise representation of data and semantics in object-oriented data models to support the integration process. Furthermore the query types that will be supported and the integration process are characterized.
The increasing use of new techniques within Geo Sciences for capturing field data, and the ongoing development of Geo Information Systems (GIS), is coupled with a growing diversity of methods such as geomorphological mapping, analyses of sediment covers, hydrological modeling or dating methods (DIKAU, 1992; VINKEN, 1992). Furthermore, capturing and analyzing data followed by knowledge based interpretations of these analyses means high investment of equipment, manpower, and specific knowledge to gain new information about natural processes. The diversity of techniques and methods leads to a vast and further growing amount of heterogeneous data that are stored in diverse formats and in different databases often even in a single research group. As a consequence high investments have been made to create central databases to avoid the loss of data as well as to get the possibility to use these data for further research in the same or different research areas. Furtheron specific query components were coupled to these databases for getting easy data access. The existence of several worldwide databases and query systems leads to a number of problems. First of all, the structure of different central databases is often diverse. Furthermore, this argument also applies to the query components. This means, to connect databases or even datasets, special transfer algorithms have to be developed and the possibility of loosing data in the sense of not getting information about their existence is high.
In 1996 a combined project named IOGIS (Interoperable Geoscientific Information Systems), consisting of six German research groups in the fields of Geography, Geology, Climatology, Computer Sciences and Remote Sensing was founded in Germany. This project, which is funded by the German Research Foundation (DFG), deals with the integration of data and methods for spatial and temporal modeling of geoscientific problems [IOGIS98]. The topics of IOGIS concentrate on object-oriented modeling, 3D/4D extensions, standardization and structuring of geoscientific methods in GIS and plausibility of Geo objects.
As a part of IOGIS the OPALIS (Open PALeoecological Information System) project aims at developing object-oriented concepts and mechanisms as well as an open GIS architecture facilitating the integrated use of isolated data pools to support Geo scientists in characterizing the temporal development of ecosystems and comparing the importance of different processes leading to actual conditions. Scope of the project is not to sample and store data in a central database like e.g. World Data Center (WDC) but to enable access to distributed, heterogeneous data by the use of integrated queries. Another advantage of the OPALIS system has to be seen in the fact, that there is no need for the owner of participating databases (research groups) to modify their own data structures like it has to be done when participating in central databases. The data documentation and modeling is done by the scientists of the OPALIS project.
One of the major problems concerning interoperability of databases or geo information systems has to be seen in the representation and translation of data semantics. Here interoperability stands for the ability of systems to exchange data and the inherent semantics to analyze a generic objective whereas integration is used as the unique way of data and method handling. Semantics in this paper is defined in case of modeling as the meaning of data objects itself, their relationship to other data objects as well as to real world objects they refer to. This supports a better expression of the mental map. Additionally we consider the definition in computer science where semantics is defined as a mathematical based interpretation of the formal language expressions of a database (LEEUWEN, 1990; BISHR; 1998).
The remainder of the paper is structured as follows: In section 2 we present the basic work of sampling and structuring data of different research groups (IGBP-PAGES) as a base for the ability to represent the correct semantics of the data in the following object models. Section 3 takes up the scope of the project again and describes the development of the object-oriented data and standard models using the Unified Modeling Language (UML). The integration process will be explained in section 4, where the query component and an example of an integrated query is presented, and in section 5 by the description of the integration process. The paper will close with conclusions and an outlook on future work.
A precondition to achieve interoperability between distributed databases is to overcome data heterogeneity. This requires a precise knowledge about the data itself, all related meta data, and the research objective of the scientists handling this data. According to BISHR (1998) all data are related to the specific "Discipline Perception World" of the scientist who captured and/or processed the data. It represents the scientists mental map of real world conditions. In the paper we call this discipline perception world as "Domain".
In case of OPALIS the domain is Geo Science with a special focus on geomorphology. Modeling domain knowledge as the central part of data modeling in OPALIS involves transferring specific knowledge of a subject into a data model. To verify the semantics of data sets like defined before the project work in OPALIS started with the sampling and documentation of existing data and data handling methods of different German research groups within the IGBP-PAGES program. The research topic of these groups is the development of sediment covers and the reconstruction of paleo surfaces in different environments.
Questionnaires were directed to different group members to get relevant information about both the aims of their research projects and meta data corresponding to the datasets that were made available to us. The datasets are founded basically on borehole data captured in different areas. Although the groups had nearly identical research topics the way of data caption, processing and storage differed widely. This is a common situation in geo sciences even if the groups would not have different domains. In our case study the 3 groups consist of soil scientists, geologists and geomorphologists. Another similarity is the fact, that all groups based their research on borehole data. Therefore it was an important aspect for the development of OPALIS to start data modeling based on one- and two-dimensional data.
The documentation of these data required the following information to ensure a detailed semantic representation: (1) central knowledge about the domain and related institutions, motivation, topic and area of research, information about data capture in the field, used equipment and other sources of primary data; (2) knowledge about the data itself, type of data (1 to 4 dimensional), representation and storage of primary data, semantic representation as well as information about data quality; (3) geometric representation; (4) knowledge about processing tools, data formats and databases used to store the data and (5) all information about knowledge based interpretations of the data.
Regarding these 5 parts of documentation, there is still one important type of information left uncovered. Within every domain there are specific standards that have to be observed. These standards are of high interest in the field of expressing and formalizing domain knowledge, data caption and processing as well as in the field of naming and defining objects.
For this reason we handle these standards separately concerning the development of the following object-oriented modeling of data. An example will be presented in section 3. The documentation of all this data information leads to a first basic data structure (see figure 1) including all associated meta information (this means "Core Meta Data" and "Domain Meta Data" with respect to the definition of the Open GIS Consortium – Open GIS Project Number 97-110R1 -) that can be transformed to the required object models.
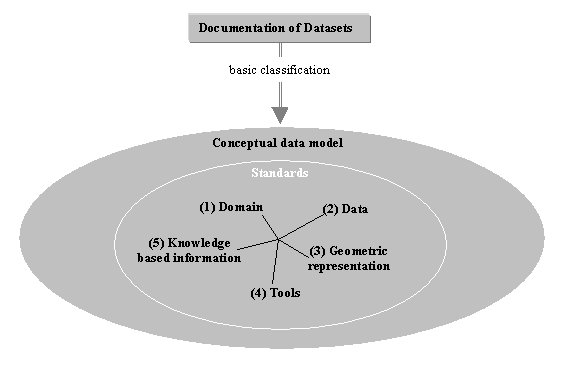
Figure 1: Main parts of the conceptual data model
By structuring the datasets the preconditions for generating a detailed data model using object-oriented modeling techniques are met. The degree of semantic representation like defined above within an object-oriented data model is a measure of the accuracy of the model that has to be achieved. The aim of object technology as a tool in developing models is often described as being enabled to understand the domain, taking into account that the development of models explicitly requires detailed knowledge about the domain. Furtheron, this way of modeling may lead to a closer approximation to real world conditions because of the consideration of the semantics of geo objects. According to WORBOYS (1994; 1995) geo data are characterized by a variety of attributes and behavioral values that define their spatial, temporal, and graphical dimensions as well as textural and numeric dimensions. The advantage of object-oriented modeling is the fact that objects encapsulate state (expressed by attributes) and behavior (specified methods/operation) and they are able to communicate by sending and retrieving messages. In recent years there are several studies about object-oriented model bases and object-oriented programming languages for the use in Geographical Information Systems (GIS) to support the modeling of environmental processes (BENNETT, ARMSTRONG & WEIRICH, 1996; HAMRE, 1994; KIDNER & JONES, 1994).
The specific use of object orientation within a GIS is not the primary scope of our project. Our aim is to realize a system that enables scientist to do integrated queries to distributed, heterogeneous databases no matter what kind of data representation they use. To solve this problem, we use object-oriented modeling for a detailed representation of single distributed datasets including all meta data that was necessary for all steps of data "handling" and representation. This means, each dataset is represented within one special data object model. Additionally every used standard that is related to the data is separately represented in a standard object model using the same modeling tool. To realize data integration there are two things to be done: (i) to represent the single data models in an integrated model and (ii) to associate the standard object models to the integrated model using a query component (see section 4).
Before modeling the datasets and the standards a common modeling language is necessary because the object models are created by Geomorphologists and should be transferred into a physical model by Computer Scientists. In spite of very good personal communication many projects profit from the use of a graphic modeling language that is able to include and express semantics of geo data without further explanation. So the syntax and the semantics of the language should be easy to learn and well known to all participants. In addition semantic modeling enables the integration of spatial and temporal data independent of implementing details like single point representations. For this reason the integration of semantics (e.g. the interaction between landslides, precipitation and soil conditions) is the base for modeling complex processes in Geosciences.
Within the OPALIS project the Unified Modeling Language (UML) (BOOCH, 1999; RUMBAUGH, 1999; JACOBSON, 1999) is used to describe the design of class hierarchies and their interacting relationships, needed to capture the knowledge relevant for integration purposes. Here are some principles for data modeling using the UML:
Classes and their associated attributes and methods describe the common properties of the respective objects. In contrast to the relational approach, where tuples with identical values cannot be distinguished, objects are identified by a special value, called object identifiers (OID), that is maintained by the system. Thus objects can be handled independent of the their actual attribute values. Classes can be organized in a specialization/generalization hierarchy. In this way common features of the data model can be described within more general classes near the top of the hierarchy, whereas special requirements can be considered in respective subclasses. As a result, all attributes and methods of the higher level classes must be valid for all subsumed classes and objects, that are instances of a certain class, can be used, whenever an instance of a super class is expected. Further more objects may be connected via different relationships. The most general relationship is the so called "association", that has to be specified depending on the semantic of the actual relationship. An "aggregation" ("part-whole-relationship") is a relationship with predefined semantics. It may for instance constrain the lifetime of the connected objects, e.g. if the object representing the "whole" is deleted, then all "part"-objects will also be destroyed.
Apart from the illustration of generalization, association and aggregation of object classes Figure 2 contains some of the redefined classes of the datasets used in the IGBP-PAGES program. While the conceptual data model is independent of any kind of database system, the task of object-oriented modeling is to create an object model that is able to be directly transferred into a physical model for a special database system. Object-based models are, like mentioned above, founded on the concept of objects that own properties, behavior and relationships with other objects in space and time. For this reason it is necessary to revise the objects of the conceptual model in view of their semantics. These specific objects and their relations are expressed using class diagrams. With respect to the complexity of the resulting data model, we are not going to describe the detailed object-oriented model in this paper. We will rather describe the fundamental assumptions that led to the final model:
It was taken into account that all datasets to be modeled are based on field work associated to the standard used for data capture (with no further specification in the data object model). To specify information that is of general interest for all related classes we derived two classes which are directly related to the data in general. (1) "Site data" - as generalization of the data itself like coordinates, map information and all data captured in the research area. (2) "Project data"- containing all information about the aim and objective of the work itself. This also includes involved persons, institutions, and research projects. The attributes and subsumed classes of (1) and (2) are clearly defined regarding the underlying dataset. The following data object model concentrates on "Site data".
Drillings, like other field data, are georeferenced. So there is a need for a class "Georeferencation" which subsumes all data within the dataset that determines the location. Used standards related to georeferencings like x/y coordinates - e.g. coordinate findings, coordinate systems, projections, used maps, etc. are represented in special standard object models and associated to the data object model by the query component (see section 4). Furtheron a class "Drillings" subsumes different classes of special drillings using different equipment respecting diverse objectives. These are associated to data basically expressed as stratigraphic information represented by different layers. Fixing stratigraphic layers always depends on the domain and its standards to capture stratigraphic information as well as on the person doing the work. These standards again are modeled separately, but all other information has to be reflected in the data object model. The layers themselves contain further information. This is expressed as classes like "Components" (related to standardized archives, e.g. Pollen data base) "Chemical analyses", "Physical analyses" or "Datings" (as generalization of different types of Datings, e.g. Dendrochronology, 14C).
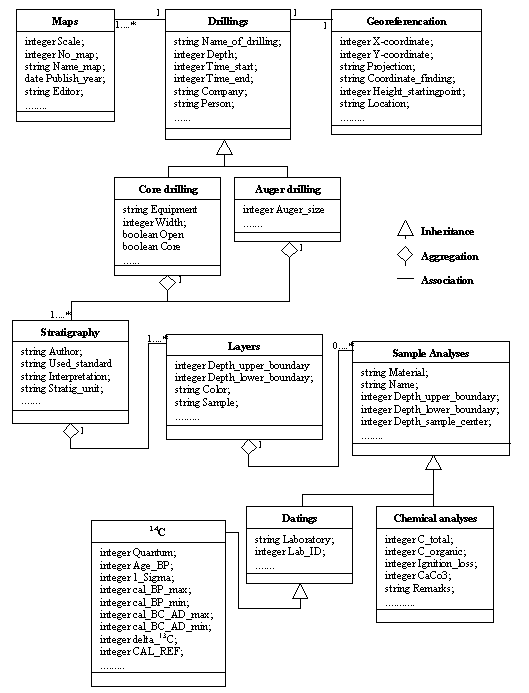
Figure 2: Basic example for a "Site data" model
A lot of these classes represent or contain discrete or continuous temporal data, that has to be integrated into the model. In the first stage of the project we handle temporal data as common objects with the attribute "time". The problem of 3D/4D extension by implementing separate spatio-temporal data models will be addressed after realizing the prototype of OPALIS which is based on one and two dimensional data in three dimensional space.
Like mentioned before data are mostly based on standards. One of the first we took into account was "Symbolschlüssel Geologie" (SSG) (PREUSS, 1991) that provides rules like e.g. naming, shortcuts, and hierarchical and temporal structures of geological data in Germany. Treating a modeling standard like SSG as a kind of dictionary does not support efficient data integration. The standards contain various rules for different types of field work. These rules and the various shortcuts are associated on different levels with the classes (especially to their attributes) of the dataset.
Using the Unified Modeling Language we created object-models for different standards like "Symbolschlüssel Geologie", "Bodenkundliche Kartieranleitung" (Bundesanstalt für Geowissenschaften und Rohstoffe, 1996) and several mapping instructions. To prepare data integration we started to build up links between the models by defining special types of queries.
Developing a query component for accessing integrated data is based on defining possible queries that may be made on the different data models. It is not realistic to anticipate all conceivable queries that may be made on datasets, why it is necessary to define possible types of queries. By analysing the questionnaires and discussing the aims of different projects we defined the following basic types of queries:
These types are prerequisite for the design of the query component. Integrated queries on objects are composed from these types so they have to be implemented before programming special queries that are focused on different values. The following example shows different possibilities of how an integrated query can be executed in OPALIS.
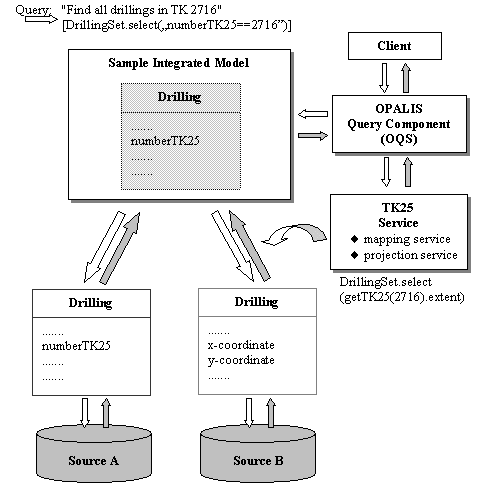
Figure 3: Example for an integrated query
Imagine an integrated query like "get all borehole data located in the area of a special topographical map, 1:25000 (TK25), No. 2716" on two distributed, heterogeneous data sets. For this example we concentrate on an attribute named "numberTK25" (here 2716). What happens, if the object model of data source A specifies this attribute and the object model of a second source B does not, because borehole data of source B are related to longitude/latitude coordinates with no relation to specific maps? By querying both sources (A+B) using the attribute mentioned above, this result would only cover borehole data from source A.
Alternatively, a spatial access query could be posed, using the attribute as the selection predicate. In this case a standard object model (e.g. TK25-Service) has to be linked to the OPALIS Query Service (OQS). This would include a "Mapping service" that provides the necessary boundary coordinates of special standard maps and a "Projection service" that is responsible for comparable coordinate values within the range of the map coordinates. Based on this, the query could be automatically transformed according to the object model of each data source. The different results computed this way can be integrated exploiting the mappings from the source models to an integrated schema. In OPALIS all integrated schemata are specified as views over the object-oriented models of source data. The specification is stored in the meta data repository of the OPALIS server.
A second possibility is the data integration prior to querying. The object model of source B could be extended with the missing attribute "numberTK25". The respective value could also be derived using the TK25-Service. Here the models representing each data source may become very large and complex. But the results of queries involving such an attribute could be computed more efficiently, due to partly precomputed predicates. The specification of integrated queries has been the first step towards data integration in the OPALIS project. The development of the query component (OQS) and its continuous evaluation are the next steps. This will involve a detailed analysis of the integration alternatives described above.
The actual integration process is performed in several steps, which correspond to the different components of the OPALIS Query Service (OQS) (fig. 4). The first integration step is implemented in the query component, which has to provide client applications with a uniform interface in order to provide integrated access to diverse data. Client applications send queries to the query component, which are checked against the integrated schema. A query is then transformed into a set of queries, each of them corresponding to the model of a single data source. This transformation process utilizes the domain knowledge describing the dependencies between integrated schema and local schemata. This knowledge includes diverse standards and their interrelationships, inter model integrity constraints, attribute name mappings, conversion function for measure units or coordinates, etc.. The generated queries are send to the respective data source via a corresponding wrapper component.
For the next step of the integration process each data source needs a connection component, called "Wrapper", which is responsible of transforming an incoming query according to the native query language of the underlying data storage system. Wrappers are on one hand composed of a generic part, which hides the particularities of the different types of storage systems and provides a uniform interface for querying and data delivery. On the other hand they export an object model depending on the respective data schema implementing a mapping from the source data model into an adequate object-oriented model. This technique reduces the costs for establishing connections from OPALIS to new data sources. The generic part merely depends on the storage system for the source data e.g. ASCII file or relational database. Hence it must be implemented only once per source system type. The schema dependent part is merely used to perform simple format testing in order to ensure a structurally correct instantiation of the respective object model. A meta object protocol and mechanisms needed to ensure certain integrity constraints are built into OPALIS providing a framework that supports the rapid realization of adequate object models.
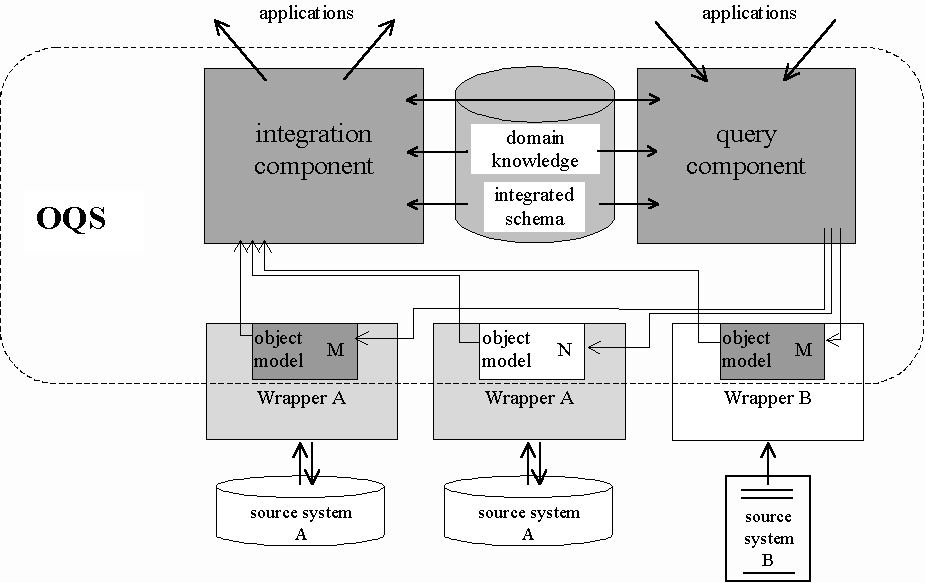
Figure 4: Information flow in the integration process
The final step, which is supported through the integration component in the OQS, principally collects the result sets received from the data sources and merges them into a single set. Thereby the information is transformed back according to the integrated schema and at last delivered to the requesting client application. Furthermore, the integration and query component have to cooperate, in case it is necessary to deal with intermediate results during the execution of a certain query.
Note that the process for semantic integration of heterogeneous data as described above does not determine the location where the integrated information will effectively reside. During the design of OPALIS we have looked into two strategies that can be associated with federated databases (CONRAD, 1997) and data warehouse systems (LABIO, 1997), respectively. Federated systems rely on data storage and maintenance at the source sites. Queries are decomposed and forwarded to the data sources. The answers are collected and integrated in real time. In this way information actuality can be ensured at the cost of generally higher response times and possibly incomplete answers due to temporarily unavailable data sources. On the other hand, data warehouses integrate and store necessary data in a central repository in advance. Therefore pre computed results are readily available at query time. This allows for relatively short response times and information derived from all source data sets. The disadvantages of this approach are storage of possibly outdated information and less flexibility. Information that was not modeled at integration time cannot be handled by the system. The problems, that systems like OPALIS have to deal with, arising from the variety of software and hardware platforms used at the source sites, as well as a possible solution based on today’s distributed object technologies like CORBA are discussed in BALOVNEV (1998).
As a result in OPALIS we are using a mixed strategy. Because of the huge amount of data and copyrights in the Geo sciences, most of the data cannot be stored in a central place. But there exists a variety of meta information, which can be computed in OPALIS, like "How many drillings stored at the connected source sites are located in a certain area?" or "Determine where data or publications about a certain project can be found?". In these cases a pure distributed approach would lead to intolerably long response times.
The aim of OPALIS to realize the integration of heterogeneous geoscientific data while using distributed data sources and to guarantee the integrity and extensibility of the system has been presented. By describing the importance of accurate object-oriented modeling we want to focus on the needs for a system that enables data integration without establishing a central database. The cooperation of Geo Scientists (OO Data Modeling) and Computer Scientists (Integration Process) is the most efficient way to handle the different aspects of data integration and the interoperability of the system. Interoperability on the semantic level is supported by modeling domain knowledge and implementing different types of queries. Building up this system accurately and realizing the first prototype based on one and two dimensional data in three dimensional space is the foundation of future work. More complex datasets that are based on three and four dimensional data will be transferred to semantically based data and standard object models to realize the 3D/4D extension of the prototype by integrating these data to the system.
The authors would like to acknowledge the cooperation with the IGBP-PAGES pilot groups of W. Andres and J. Wunderlich (University Frankfurt/Marburg), H. Streif and Ch. Hoselmann (NLfB Hannover), and G. Wagner and A. Lang (MPI and University of Heidelberg). We are also indebted to M. Assmann, J. Brinkmann, C. Michels and U. Radetzki for their implementation and modeling support.
[IOGIS98] IOGIS – Vision about a new generation of interoperable GIS. In German. Report of the participating groups at the Universities of Berlin, Bonn, Berlin/Bonn, Freiburg, Münster and Stuttgart.
Balovnev, O., Bergmann, A., Breunig, M., Cremers, A.B. & S. Shumilov (1998): A CORBA-based approach to data and systems integration for 3D geoscientific applications, in: Proceedings of the 8th Intern. Symposium on Spatial Data Handling, Vancouver, Canada.
Bennett, D.A., Armstrong, M.P. & F. Weirich (1996): An Object-Oriented Model Base Management System for Environmental Simulation. In: Goodchild, M.F. et al (eds.): GIS and Environmental Modeling: Progress and Research Issues, p. 439-443, GIS-World Books
Bishr, Y. (1998): Overcoming the semantic and other barriers to GIS interoperability. In: International Journal of Geographical Information Science, Vol. 12, No. 4, p. 299 - 314. Taylor & Francis, London.
Booch, G., Rumbaugh, J. & I. Jacobson (1999): The Unified Modeling Language User Guide. Addison-Wesley Object Technology Series, 512 p.
Bundesanstalt für Geowissenschaften und Rohstoffe & Geologische Landesämter der Bundesrepublik Deutschland (Hrsg.) (1996): Bodenkundliche Kartieranleitung. 4. Auflage, Hannover, 392 p.
Conrad, St. (1997): Federated Database Systems – Concepts of Data Integration, Springer, 331 p.
Dikau, R. (1992): Aspects of constructing a digital geomorphological base map. Geologisches Jahrbuch, A122, pp. 357-370.
Hamre, T. (1994): An object-oriented conceptual model for measured and derived data variying in 3D space and time. In: Waugh, T.C. & R.G. Healey (eds.): Advances In GIS Research Proceedings, Vol. 2, p. 868-881. SDH94, Sixth International Symposium on Spatial Data Handling, Edinburgh, UK.
Jacobson, I., Booch, G. & J. Rumbaugh (1999): The Unified Software Development Process. Addison-Wesley Object Technology Series, 512 p.
Kidner, D.B. & C.J. Jones (1994):A deductive object-oriented GIS for handling multiple representations. In: Waugh, T.C. & R.G. Healey (eds.): Advances In GIS Research Proceedings, Vol. 2, p. 882-900. SDH94, Sixth International Symposium on Spatial Data Handling, Edinburgh, UK.
Labio, W.J., Zhuge, Y., Wiener, J.L., Gupta, H., Garcia-Molina, H. & J. Widom (1997): The WHIPS Prototype for Data Warehouse Creation and Maintenance, in: Proceedings of the ACM SIGMOD Conference, Tuscon, Arizona.
Leeuwen, J. (1990): Formal models and semantics. Handbook of Theoretical Computer Science, XIV, Cambridge, USA, MIT-Press.
Preuss, H., Vinken, R. & H.-H. Voss (1991): Symbolschlüssel Geologie. Niedersächsisches Landesamt für Bodenforschung und Bundesanstalt für Geowissenschaften und Rohstoffe (Hrsg.), Hannover, 328 p.
Rumbaugh, J., Jacobson, I. & G. Booch (1999): The Unified Modeling Language Reference Manual. Addison-Wesley Object Technology Series, 576 p.
Vinken, R. (Ed.) (1992): From Geoscientific Map Series to Geo Information Systems. Geologisches Jahrbuch, A 122, Hannover, 501 p.
Worboys, M.F. (1994): Object Oriented Approaches to Geo-referenced Information. In: International Journal of Geographical Information Systems, Vol. 4, p. 385-399. Taylor & Francis, London.
Worboys, M.F. (1995): GIS - A Computing Perspective. Taylor & Francis, London, 376 p.