Return to GeoComputation 99 Index
Manfred M. Fischer and Martin Reismann
Department of Economic and Social Geography, Wirtschaftsuniversitaet Wien,
Augasse 2-6, A-1090 Vienna, Austria
E-mail: Manfred.M.Fischer@wu-wien.ac.at
E-mail: reismann@wigeo1.wu-wien.ac.at
Katerina Hlavácková-Schindler
Institute of Computer Science, Academy of Sciences of the Czech Republic,
Pod Vodárenskou vezí 2, 18207 Praha 8, Czech Republic
E-mail: katka@uivt.cas.cz
Parameter estimation is one of the central issues in neural spatial interaction modelling. Current practice is dominated by gradient-based local minimization techniques. They find local minima efficiently and work best in unimodal minimization problems, but can get trapped in multimodal problems. Global search procedures provide an alternative optimization scheme that allows it to escape from local minima. Differential Evolution has been recently introduced as an efficient direct search method for optimizing real-valued multimodal objective functions (Storn and Price 1996). The method is conceptually simple and attractive, but little is known about its behaviour in real world applications. This paper explores this method as an alternative to current practice for solving the parameter estimation task, and attempts to assess its robustness, measured in terms of in-sample and out-of-sample performance. A benchmark comparison with back propagation of conjugate gradients illustrates the superiority of Differential Evolution.
The development of spatial interaction models is one of the major intellectual achievements and, at the same time, perhaps the most useful contribution of spatial analysis to social science literature. Since the pioneering work of Wilson (1970) on entropy maximization, there have been surprisingly few innovations in the design of spatial interaction models. The competing destinations version of Fotheringham (1983), the application of feed-forward neural networks (Openshaw 1993, Fischer and Gopal 1994), the use of genetic algorithms and genetic programming to breed new forms of spatial interaction models (Openshaw 1988, Diplock 1996, Turton, Openshaw and Diplock 1997) and neural network topology optimization (Fischer and Leung 1998) are the principal exceptions.
Neural spatial interaction models are termed neural in the sense that they are based on neural computational models, inspired by neuroscience. They are closely related to spatial interaction models of the gravity type, and can be understood as a special class of general feed-forward neural network models with a single hidden layer and sigmoidal transfer functions (Fischer 1998). This class of networks can provide approximation within an arbitrary precision (i.e., it has universal approximation property), as proven by Hornik et al. (1989).
Learning from examples, the problem for which feed-forward neural networks were designed in order to solve, is one of the most important research topics in artificial intelligence. A possible way to formalize learning from examples is to assume the existence of a function representing the set of examples, thus, enabling it to generalize. This can be called a function reconstruction from sparse data (or in mathematical terms, depending on the required precision, approximation or interpolation problem, respectively). Within this general framework, the main issues of interest are the representational capabilities of a given network model and the procedures for obtaining the optimal network parameters. In this contribution, the second issue, network training (i.e., parameter estimation), will be addressed.
Many training (learning) methods find their roots in function minimization algorithms, which can be classified as local or global minimization algorithms. Local minimization algorithms, such as the gradient descent and the conjugate gradient methods (for more details, see e.g., Fischer and Staufer 1999), are fast, but usually converge to local minima. In contrast, global minimization algorithms give better results, because in principle they can escape from local error minima. The computational cost for a single run of a global optimization routine is usually high (Fischer, Hlavackova-Schindler and Reismann 1999).
The next section provides a summarized description of single hidden layer neural spatial interaction models (Section 2). The parameter estimation problem is defined in Section 3 as a problem of minimizing the sum-of-squares error function along with a brief characterization of local search procedures that are generally used to solve this problem. Differential Evolution is outlined in some detail in Section 4. The testbed used for the evaluation of this parameter estimation procedure is Austrian interegional tele-communication traffic data (see Fischer and Gopal 1994), because this data set is known to pose a difficult problem to neural networks using gradient-based learning due to multiple local minima. Section 5 reports on a set of experimental tests carried out to identify an optimal parameter setting and assesses the efficacy of the DEM approach compared to multistart of back propagation of conjugate gradients. Section 6 summarizes the results achieved.
Suppose we are interested in approximating an N-dimensional spatial interaction function ![]() , where
, where ![]() as N-dimensional Euclidean real space is the input space and
as N-dimensional Euclidean real space is the input space and ![]() as 1-dimensional Euclidean real space is the output space. This function should estimate spatial interaction flows from regions of origin to regions of destination. (In practice, only bounded subsets of the spaces are considered.) The function F is not explicitly known, but given by a finite set of samples S = {(xk, yk), k = 1,..., K}, so that F(xk) = yk, k = 1,..., K. The set S is the set of pairs of input and output vectors. The task is to find a continuous function which approximates (or interpolates) set S. In real world applications, K is a small number and the samples contain noise.
as 1-dimensional Euclidean real space is the output space. This function should estimate spatial interaction flows from regions of origin to regions of destination. (In practice, only bounded subsets of the spaces are considered.) The function F is not explicitly known, but given by a finite set of samples S = {(xk, yk), k = 1,..., K}, so that F(xk) = yk, k = 1,..., K. The set S is the set of pairs of input and output vectors. The task is to find a continuous function which approximates (or interpolates) set S. In real world applications, K is a small number and the samples contain noise.
To approximate F, we consider the class of neural spatial interaction models ![]() with one hidden layer, N input units, J hidden units and one output unit.
with one hidden layer, N input units, J hidden units and one output unit. ![]() consists of a composition of transfer functions so that the (single) output y of
consists of a composition of transfer functions so that the (single) output y of ![]() is
is
![]() .
.
Vector x = (x0,..., xN) is the input vector augmented with a bias signal x0 which can be thought as being generated by a 'dummy unit' whose output is clamped at 1. The wjn's represent input to hidden connection weights and the wj's hidden to output weights (including the biases). The symbol w is a convenient shorthand notation of the d = (J · (N + 1) + J + 1)-dimensional vector of all the wjn and wj network weights and biases (i.e. model parameters). ![]() and
and ![]() are differentiable non-linear transfer functions of the hidden units j = 1,..., J and the output unit, respectively. Following Fischer and Gopal (1994), we will consider only the case N = 3, i.e., the input space will be a closed interval of the three dimensional Euclidean space
are differentiable non-linear transfer functions of the hidden units j = 1,..., J and the output unit, respectively. Following Fischer and Gopal (1994), we will consider only the case N = 3, i.e., the input space will be a closed interval of the three dimensional Euclidean space ![]() . The three input units correspond to the independent variables of the classical unconstrained spatial interaction model of the gravity type. They represent measures of origin propulsiveness, destination attractiveness, and spatial separation. The output unit corresponds to the dependent variable of the classical model and represents the spatial interaction flows from origin to destination.
. The three input units correspond to the independent variables of the classical unconstrained spatial interaction model of the gravity type. They represent measures of origin propulsiveness, destination attractiveness, and spatial separation. The output unit corresponds to the dependent variable of the classical model and represents the spatial interaction flows from origin to destination.
One of the major issues in neural spatial interaction modelling includes the problem of selecting an appropriate member of model class ![]() in view of a particular real world application. This model specification problem includes both the choice of appropriate transfer functions
in view of a particular real world application. This model specification problem includes both the choice of appropriate transfer functions ![]() and
and ![]() and the determination of an adequate network topology of
and the determination of an adequate network topology of ![]() (i.e., the number of hidden units J). Clearly, the model choice problem and the parameter estimation problem, i.e., the determination of an optimal set of model parameters, are intertwined in the sense that if a good model specification can be found, the success of which depends on the particular problem, then the step of parameter estimation (also termed network training), may become easier to perform.
(i.e., the number of hidden units J). Clearly, the model choice problem and the parameter estimation problem, i.e., the determination of an optimal set of model parameters, are intertwined in the sense that if a good model specification can be found, the success of which depends on the particular problem, then the step of parameter estimation (also termed network training), may become easier to perform.
In this contribution we focus only on the parameter estimation problem. Without loss of generality, we assume the transfer functions ![]() for all j = 1,..., J, and equal to the logistic function, thus, consider the special class
for all j = 1,..., J, and equal to the logistic function, thus, consider the special class ![]() of functions
of functions ![]() :
:
![]() .
.
The approximation of ![]() then merely depends on the learning samples S, and the learning (training) algorithm that determines the parameter vector w from S and the number J of hidden units.
then merely depends on the learning samples S, and the learning (training) algorithm that determines the parameter vector w from S and the number J of hidden units.
Without loss of generality, we assume the neural spatial interaction model to have fixed topology, i.e., J is predetermined. Then, the goal of learning is to find suitable values w* for the network weights of the model such that the underlying mapping ![]() represented by the training set
represented by the training set ![]() , is approximated or learned, where k is the index of the training instance. yk represents the desired network output (i.e. the spatial interaction flows) corresponding to xk, k = 1,..., K. The process of determining optimal parameter values is called training or learning and can be formulated in terms of minimization of an appropriate error function (or cost function) E to measure the degree of approximation with respect to the actual setting of network weights. The most commonly used error function is the squared-error function of the patterns over the finite set of training data, so that the parameter estimation problem may be defined as the following minimization problem
, is approximated or learned, where k is the index of the training instance. yk represents the desired network output (i.e. the spatial interaction flows) corresponding to xk, k = 1,..., K. The process of determining optimal parameter values is called training or learning and can be formulated in terms of minimization of an appropriate error function (or cost function) E to measure the degree of approximation with respect to the actual setting of network weights. The most commonly used error function is the squared-error function of the patterns over the finite set of training data, so that the parameter estimation problem may be defined as the following minimization problem
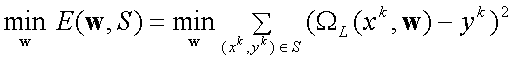 ,
,
where the minimization parameter is the weight vector w that defines the search space. In this way, the problem of network training has been formulated in terms of minimization of the error function E. This error function is a function of the adaptive model parameters, i.e., network weights and biases. The derivatives of this function with respect to the model parameters can be obtained in a computationally efficient way using the back-propagation technique (see, e.g., Gopal and Fischer 1996; and Fischer and Staufer 1999, for more details). The minimization of continuous differentiable functions of many variables is a problem that has been widely studied, and many of the non-linear minimization algorithms available are directly applicable to the training of neural spatial interaction models as described in Section 2. The general scheme of these algorithms can be formulated as follows:
(i) Choose an initial vector w in parameter space and set t = 1;
(ii) Determine a search direction d(t) and a step size ![]() so that
so that
![]() , t = 1, 2,...;
, t = 1, 2,...;
(iii) Update the parameter vector
![]() , t = 1, 2,...;
, t = 1, 2,...;
(iv) If ![]() then set t = t + 1 and go to (ii), else return w(t + 1) as the desired minimum.
then set t = t + 1 and go to (ii), else return w(t + 1) as the desired minimum.
In this study we refer to the Polak-Ribiere variant of the conjugate gradient (CG) procedure (Press et al. 1992), a mature local optimization method, which is used as a benchmark in Section 5. This algorithm computes the sequence of search directions as
![]() , t = 1, 2,...;
, t = 1, 2,...;
with
![]() ,
,
where ![]() is a scalar parameter in the form
is a scalar parameter in the form
![]() for t = 1, 2,...,
for t = 1, 2,...,
w(t - 1)T is the transpose of w(t - 1). The definition (8) of ![]() guarantees that for the sequence of vectors d(t)
guarantees that for the sequence of vectors d(t) ![]() holds. The parameter
holds. The parameter ![]() is chosen to minimize
is chosen to minimize
![]() for t = 1, 2,...
for t = 1, 2,...
in the t-th iteration. This gives the automatic procedure for setting the step length, once the search direction d(t) has been determined.
This and other local optimization methods tend to have difficulties, when the surface is flat (i.e., gradient is close to zero), when gradients are in a large range, and when the surface is very rugged. When gradients vary greatly, the search may progress too slowly, when the gradient is small and may overshoot where the gradient is large. When the error surface is rugged, a local search from a random starting point generally converges to a local minimum close to the initial point with a worse solution than the global minimum.
Global search algorithms employ heuristics to allow escape from local minima. These algorithms can be classified as probabilistic or deterministic. Of the few deterministic global minimization methods developed, most apply deterministic heuristics to bring search out of a local minimum. Other methods, such as covering methods, recursively partition the search space into subspaces before searching. None of these methods operate well or provide adequate coverage when the search space is large as is usually the case in neural spatial interaction modelling.
Probabilistic global minimization methods rely on probability to make decisions. The simplest probabilistic algorithm uses restarts to bring a search out of a local minimum when little improvement can be made locally. More advanced methods rely on probability to indicate whether a search should ascend from a local minimum: simulated annealing, for example, when it accepts uphill movements. Other probabilistic algorithms rely on probability to decide which intermediate points to interpolate as new trial parameter vectors: random recombinations and mutations in evolutionary algorithms (see for example, Fischer and Leung 1998).
Central to global search procedures is a strategy that generates variations of the parameter vectors. Once a variation is generated, a decision has to be made whether or not to accept the newly derived trial parameter. Standard direct search methods (with few exceptions such as simulated annealing) use the greedy criterion to make the decision. Under this criterion, a new parameter vector is accepted if and only if it reduces the value of the error function. Although this decision process converges relatively fast, it has the risk of entrapment in a local minimum. Some stochastic search algorithms, such as genetic algorithms, and evolution strategies, employ a multipoint search strategy in order to escape from local minima.
The Differential Evolution Method (DEM), originally developed by Storn and Price (1996, 1997) is a global optimization algorithm that employs a structured, yet randomized parallel, multipoint search strategy, which is biased towards reinforcing search points at which the error function E(w) being minimized has relatively low values. DEM is similar to simulated annealing in that it employs a random (probabilistic) strategy. One of the apparent distinguishing features of DEM is its effective implementation of the parallel multipoint search. DEM maintains a collection of samples from the search space rather than a single point. This collection of samples is called population of trial solutions.
To start the stochastic multipoint search, an initial population P of, say M, d-dimensional parameter vectors P(0) = {w0(0),..., wM-1(0)} is created. For the parameter estimation problem at hand d = (5 · J) + 1. Usually this initial population is created randomly because it is not known a priori, where the globally optimal parameter is likely to be found in the parameter space. If such information is given it may be used to bias the initial population towards the most promising regions of the search space by adding normally distributed random deviations to this a priori given solution candidate. From this initial population, subsequent populations P(1), P(2),..., P(t),... will be computed by a scheme that generates new parameter vectors by adding the weighted difference of two vectors to a third. If the resulting vector yields a lower error function value than a predetermined population member, the newly generated vector will replace the vector that it was compared to, otherwise the old vector is retained. Similarly to evolution strategies, the greedy criterion is used in the iteration process and the probability distribution functions determining vector distributions are not a priori given. The scheme for generating P(t + 1) from P(t) may be summarized by two major stages: the construction of v(t + 1)-vectors from vector w(t)-vectors (stage 1), and the decision criterion whether or not the v(t + 1) - vectors should become members of the population (stage 2) representing possible solutions of the parameter estimation problem under consideration at step t + 1 of the iteration process.
Stage 1: For each population member wm(t), m = 0, 1,...,.M - 1, a perturbed vector vm(t + 1) is generated according to
vm(t + 1) = wbest(t) + Q · (wr1(t) - wr2(t))
with r1, r2 integers chosen randomly from {0,...,.M -1} and mutually different. These integers also are different from the running index m. Q ![]() (0, 2] is a real constant factor that controls the amplification of the differential variation (wr1(t) - wr2(t)). The parameter vector wbest(t) which is perturbed to yield vm(t + 1) is the best parameter vector of population P(t).
(0, 2] is a real constant factor that controls the amplification of the differential variation (wr1(t) - wr2(t)). The parameter vector wbest(t) which is perturbed to yield vm(t + 1) is the best parameter vector of population P(t).
Stage 2:The decision whether or not vm(t + 1) should become a member of P(t + 1), is based on the greedy criterion. If
E(vm(t + 1)) < E(wm(t))
then vm(t + 1) is assigned to wm(t + 1) otherwise the old value wm(t) is retained as wm(t + 1).
The algorithm is stopped after a fixed number of iterations.
This section presents results of experiments and describes the performance of the Differential Evolution Method to solve the parameter estimation problem (3) for neural spatial interaction models (2) with three inputs, a single hidden layer with a fixed number of hidden units and a single output unit. The output unit represents the intensity of telecommunication flows from one origin region to a destination region, and the input units of the three independent variables of the classical gravity model: the potential pool of telecommunication activities in the origin region, the potential draw of telecommunication activities in the destination region, and a factor representing the inhibiting effect of geographic separation from the origin to the destination region. The ultimate goal of such neural spatial interaction models is to exhibit good generalization performance, i.e., to make good predictions for new inputs. The spatial interaction modelling prediction accuracy (generalization measured in terms of out-of-sample performance) is generally more important than fast learning.
The model performance is measured in this study by the average relative variance ARV(S) of a set S of patterns given by (Fischer and Gopal 1994)
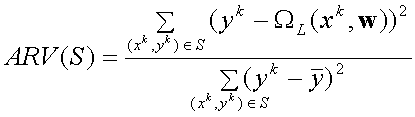
where yk denotes the target value and ![]() the average over the K desired values in S. ARV(S) provides a normalized mean squared error metric for assessing the in-sample and out-of-sample performance of trained neural spatial interaction models. ARV(S) = 1 if the estimate is equivalent to the mean of the data (i.e,
the average over the K desired values in S. ARV(S) provides a normalized mean squared error metric for assessing the in-sample and out-of-sample performance of trained neural spatial interaction models. ARV(S) = 1 if the estimate is equivalent to the mean of the data (i.e, ![]() (xk, w) =
(xk, w) = ![]() ). In the following experiments, the ARV set {ARV1, ARV2} will refer to the average relative error corresponding to the {training set, test set}.
). In the following experiments, the ARV set {ARV1, ARV2} will refer to the average relative error corresponding to the {training set, test set}.
The experiments were conducted using Austrian telecommunication flow data (see Fischer and Gopal 1994 for more details). The data set was constructed from three data sources: a (32, 32)-interregional telecommunication flow matrix, a (32, 32)-distance matrix, and gross regional products for the 32 telecommunication regions. It contains 992 4-tuples (x1, x2, x3, y), where the first three components represent the input vector x = (x1, x2, x3) and the last component the target output of the neural spatial interaction model, i.e., the telecommunication intensity from one region of origin to another region of destination. (Input and target output data were preprocessed to logarithmically transformed data scaled into [0, 1].) The telecommunication data stem from network measurements of carried telecommunication traffic in Austria in 1991, in terms of erlang, which is defined as the number of phone calls (including facsimile transmission) multiplied by the average length of the call (transfer) divided by the duration of measurement. This data set was randomly and disjointedly divided into two separate subsets: about two thirds of the data were used for parameter estimation only, and one third as a test set for assessing the generalization performance. In comparison to Fischer and Gopal (1994), the data used were updated to take some measurement errors into account. Consequently, the results of the experimental work described below cannot be directly compared to the previous results.
To get an optimal solution, it is necessary to use reliable settings for the control parameters Q and M, and an optimal number of hidden units J. There is no other way to a priori define useful combinations of control parameter values than by extensive computational simulation. In order to identify good settings, simulation runs with different combinations of parameter values have been performed. Since every function evaluation has the same complexity, iterations to converge to the optimal ARV2 value were used as a measure of learning time. Simulation runs, which did not converge within 7,000 iterations, were stopped. (Note that population size M multiplied by the number of iterations gives the number of function evaluations.) Each experiment (i.e., a fixed combination of DEM control parameter values) was repeated six (ten) times, the network model being initialized with a different set of random weights from [-0.3, 0.3] before each trial. Simulation runs were realized on PC Pentium 400 Mhz and partly on DEC Alpha 375 Mhz using the egcs-1.0.3 C-compiler.
Table 1 presents the results of the first series of experiments illustrating the effect of the Q-parameter [0.7, 0.8, 0.9, 1.0, 1.1] that controls the amplification of the differential mutation. The cardinality M of the population was set to M = 1000. A fixed topology of 10 hidden units is assumed. In-sample (out-of-sample) performance is measured in terms of ARV1 (ARV2).
There is strong evidence of the robustness of the algorithm (measured in terms of standard deviation) both with respect to the choice of the DEM-parameter Q and to the choice of the initial random state of the simulation runs. Q = 0.9 leads to the best result in terms of average out-of-sample performance (ARV2 = 0.2280). Results for Q = 1.0 are inferior (ARV2 = 0.2440). Even though there is no evidence that Q = 0.9 outperforms other settings such as Q = 0.7, 0.8 and 1.1 in a statistically significant way. Q = 0.9 has been deliberately chosen for the second series of experiments.
|
Control Parameter Q
Trial FE ARV1 ARV2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Q = 0.7 |
1 |
181 |
|
0.2137 |
|
0.2322 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
2 |
116 |
|
0.2195 |
|
0.2327 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
3 |
152 |
|
0.2080 |
|
0.2273 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
4 |
350 |
|
0.2106 |
|
0.2298 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
5 |
128 |
|
0.2122 |
|
0.2326 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
6 |
373 |
|
0.2042 |
|
0.2274 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Average |
217 |
± 156 |
0.2114 |
(0.0047) |
0.2304 |
(0.0023)
|
Q = 0.8
|
1
|
2018
|
|
0.1988
|
|
0.2297
|
|
|
2
|
813
|
|
0.2128
|
|
0.2327
|
|
|
3
|
705
|
|
0.2047
|
|
0.2328
|
|
|
4
|
543
|
|
0.2080
|
|
0.2323
|
|
|
5
|
5474
|
|
0.1912
|
|
0.2263
|
|
|
6
|
440
|
|
0.2128
|
|
0.2305
|
|
|
Average
|
1666
|
± 3809
|
0.2047
|
(0.0077)
|
0.2307
| (0.0023)
|
Q = 0.9
|
1
|
1218
|
|
0.2152
|
|
0.2341
|
|
|
2
|
456
|
|
0.2183
|
|
0.2301
|
|
|
3
|
4590
|
|
0.1841
|
|
0.2162
|
|
|
4
|
622
|
|
0.2149
|
|
0.2335
|
|
|
5
|
1371
|
|
0.2111
|
|
0.2244
|
|
|
6
|
3228
|
|
0.1912
|
|
0.2294
|
|
|
Average
|
1931
|
± 2659
|
0.2058
|
(0.0132)
|
0.2280
| (0.0062)
|
Q = 1.0
|
1
|
250
|
|
0.2426
|
|
0.2531
|
|
|
2
|
207
|
|
0.2305
|
|
0.2360
|
|
|
3
|
236
|
|
0.2297
|
|
0.2378
|
|
|
4
|
507
|
|
0.2255
|
|
0.2384
|
|
|
5
|
111
|
|
0.2459
|
|
0.2621
|
|
|
6
|
597
|
|
0.2246
|
|
0.2364
|
|
|
Average
|
318
|
± 279
|
0.2331
|
(0.0082)
|
0.2440
| (0.010)
|
Q = 1.1
|
1
|
2678
|
|
0.2121
|
|
0.2312
|
|
|
2
|
6089
|
|
0.2068
|
|
0.2235
|
|
|
3
|
390
|
|
0.2294
|
|
0.2326
|
|
|
4
|
4243
|
|
0.2174
|
|
0.2311
|
|
|
5
|
884
|
|
0.2227
|
|
0.2317
|
|
|
6
|
4846
|
|
0.2146
|
|
0.2326
|
|
|
Average
|
3188
|
± 2901
|
0.2172
|
(0.0073)
|
0.2304
|
(0.0032) |
The second series of experiments (Table 2) involves variation of the population size M, with a range of M = 50, 100, 200, 400, and 1,000. The Q-parameter was set at value Q = 0.9 and the network topology is still fixed at 10 hidden units. The results obtained are summarized in Table 2. Two observations are noteworthy: First, larger populations of parameter vectors tend to provide better results, because a large population is more likely to contain representatives from a larger number of hyperplanes. But the computational cost of evolving large populations does not seem to be rewarded by a comparable out-of-sample improvement of the solutions obtained, for M > 400. In fact, for M = 200 [400] we obtained an average ARV2 of 0.2276 [0.2279], while for M = 1000 we obtained ARV2 = 0.2280, averaged over the six trials. For the next experiments M = 400 will be used because its average computational effort (945000 function evaluations) is not much higher than the average computational effort of M = 200 (612000 function evaluations).
|
Population Size
Trial FE ARV1 ARV2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
M = 50 |
1 |
145 |
|
0.2291 |
|
0.2324 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
2 |
116 |
|
0.2264 |
|
0.2390 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
3 |
10 |
|
0.2092 |
|
0.2446 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
4 |
48 |
|
0.2250 |
|
0.2363 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
5 |
294 |
|
0.2244 |
|
0.2325 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
6 |
49 |
|
0.2229 |
|
0.2421 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Average |
110 |
± 184 |
0.2262 |
(0.0023) |
0.2378 |
(0.0046)
|
M = 100
|
1
|
306
|
|
0.2191
|
|
0.2357
|
|
|
2
|
51
|
|
0.2205
|
|
0.2257
|
|
|
3
|
192
|
|
0.2206
|
|
0.2351
|
|
|
4
|
44
|
|
0.2246
|
|
0.2349
|
|
|
5
|
28
|
|
0.2348
|
|
0.2340
|
|
|
6
|
549
|
|
0.2167
|
|
0.2379
|
|
|
Average
|
195
|
± 354
|
0.2227
|
(0.0059)
|
0.2339
| (0.0038)
|
M = 200
|
1
|
778
|
|
0.2068
|
|
0.2231
|
|
|
2
|
152
|
|
0.2182
|
|
0.2307
|
|
|
3
|
1240
|
|
0.2087
|
|
0.2276
|
|
|
4
|
64
|
|
0.2256
|
|
0.2287
|
|
|
5
|
990
|
|
0.2128
|
|
0.2295
|
|
|
6
|
447
|
|
0.2095
|
|
0.2258
|
|
|
Average
|
612
|
± 628
|
0.2136
|
(0.0065)
|
0.2276
| (0.0025)
|
M = 400
|
1
|
493
|
|
0.2128
|
|
0.2332
|
|
|
2
|
1320
|
|
0.2070
|
|
0.2265
|
|
|
3
|
130
|
|
0.2217
|
|
0.2317
|
|
|
4
|
1530
|
|
0.2088
|
|
0.2237
|
|
|
5
|
716
|
|
0.2128
|
|
0.2277
|
|
|
6
|
1483
|
|
0.2052
|
|
0.2249
|
|
|
Average
|
945
|
± 815
|
0.2114
|
(0.0054)
|
0.2279
| (0.0035)
|
M = 1000
|
1
|
1218
|
|
0.2152
|
|
0.2341
|
|
|
2
|
456
|
|
0.2183
|
|
0.2301
|
|
|
3
|
4590
|
|
0.1841
|
|
0.2162
|
|
|
4
|
622
|
|
0.2149
|
|
0.2335
|
|
|
5
|
1371
|
|
0.2111
|
|
0.2244
|
|
|
6
|
3328
|
|
0.1912
|
|
0.2294
|
|
|
Average
|
1931
|
± 2659
|
0.2058
|
(0.0132)
|
0.2280
|
(0.0062) |
Table 3 illustrates the influence of the number of hidden units J, which determines the size of the network. It can be easily seen, that a network topology with 8 hidden units seems to slightly outperform other topologies in terms of out-of-sample-performance. The best configuration of control parameters, which we obtained by successive adjustment, is presented in Table 4.
|
Number of Hidden Units
FE ARV1 ARV2 | ||||||
|
J = 3 |
228 |
± 786 |
0.2204 |
(0.0035) |
0.2335 |
(0.0020) |
|
J = 4 |
194 |
± 354 |
0.2190 |
(0.0054) |
0.2332 |
(0.0014) |
|
J = 5 |
291 |
± 450 |
0.2149 |
(0.0055) |
0.2322 |
(0.0025) |
|
J = 6 |
498 |
± 874 |
0.2123 |
(0.0039) |
0.2310 |
(0.0033) |
|
J = 7 |
820 |
± 1399 |
0.2135 |
(0.0081) |
0.2309 |
(0.0027) |
|
J = 8 |
1001 |
± 1777 |
0.2071 |
(0.0111) |
0.2246 |
(0.0086) |
|
J = 9 |
713 |
± 1156 |
0.2120 |
(0.0064) |
0.2303 |
(0.0039) |
|
J = 10 |
716 |
± 1591 |
0.2152 |
(0.0072) |
0.2304 |
(0.0037) |
|
J = 11 |
888 |
± 1611 |
0.2118 |
(0.0060) |
0.2306 |
(0.0064) |
|
J = 12 |
953 |
± 1723 |
0.2142 |
(0.0091) |
0.2282 |
(0.0060) |
|
J = 13 |
760 |
± 1372 |
0.2116 |
(0.0075) |
0.2308 |
(0.0036) |
|
J = 14 |
741 |
± 1213 |
0.2145 |
(0.0072) |
0.2294 |
(0.0038) |
|
Model Parameter
Value Q 0.9 M 400 J 8 |
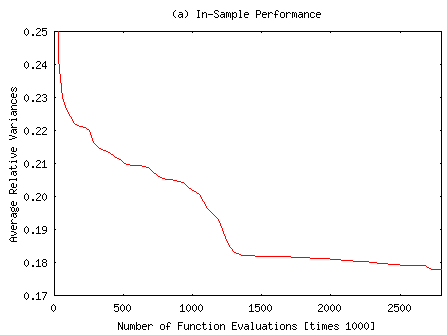
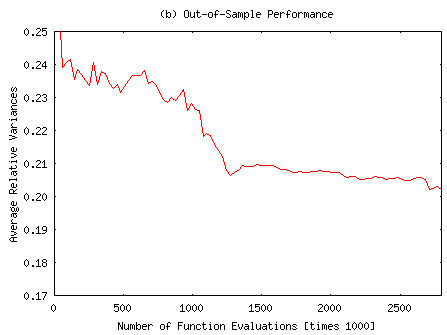
For graphical presentation, ARV1 and ARV2 indices of the most successful simulation run were plotted against learning time, measured in terms of the number of function evaluations (see Figure 1). It can be easily seen that out-of-sample performance usually lags behind in-sample performance. The configuration shown in Figure 1 does not converge within 7,000 iterations (= 2800000 function evaluations at M = 400). Continued training would give even better results.
|
|
|
|
|
|
|
|
For comparison purposes, we implemented multistart of the conjugate gradient method as a benchmark. Simulation runs were executed using the batch mode of operation and giving approximately the same computing time to the CG multistart method, which is on average needed by the optimal DEM-configuration (see Table 4) to converge. Within the time amount needed for one simulation of DEM, it is possible to execute 6 restarts of CG. So each simulation of DEM has to compete with the best of 6 trials of CG. The results of the benchmark comparison are summarized in Table 5.
|
Method
Trial ARV1 ARV2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Differential Evolution |
1 |
0.2249 |
|
0.2288 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Method |
2 |
0.2042 |
|
0.2165 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Q = 0.9 |
3 |
0.2064 |
|
0.2279 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
M = 400 |
4 |
0.2092 |
|
0.2237 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
J = 8 |
5 |
0.2069 |
|
0.2272 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
6 |
0.2124 |
|
0.2277 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
7 |
0.2102 |
|
0.2292 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
8 |
0.1778 |
|
0.2021 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
9 |
0.2109 |
|
0.2319 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
10 |
0.2084 |
|
0.2313 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Average |
0.2071 |
(0.0111) |
0.2246 |
(0.0086)
|
Conjugate Gradients
|
1
|
0.2159
|
|
0.2343
|
|
Multistart Method
|
2
|
0.2111
|
|
0.2305
|
|
(best of 6 trials)
|
3
|
0.2135
|
|
0.2331
|
|
|
4
|
0.2107
|
|
0.2324
|
|
|
5
|
0.2157
|
|
0.2352
|
|
|
6
|
0.2138
|
|
0.2323
|
|
|
7
|
0.2145
|
|
0.2338
|
|
|
8
|
0.2121
|
|
0.2320
|
|
|
9
|
0.2163
|
|
0.2365
|
|
|
10
|
0.2148
|
|
0.2341
|
|
|
Average
|
0.2138
|
(0.0019)
|
0.2334
|
(0.0016) |
DEM exhibits statistically significant superiority in terms of out-of-sample performance (MANN-WHITNEY U = 2.0, Sig. 0.0). The average ARV2 is 0.2246 [DEM] and 0.2334 [multistart of conjugate gradients]. DEM is rather stable over the different trials and clearly outperforms multistart of CG provided that the time limit is large.
This contribution uses a global search approach, called Differential Evolution Method, suitable for minimizing non-linear and [non-]differentiable functions, such as the squared error function (see equation (3)). Little is known about the behaviour of this global search procedure in real world applications.
The method uses a population of trial vectors, which are members of different local minimizers, thus, providing the possibility of escaping from suboptimal local solutions. The algorithm employs a very simple and straightforward strategy. Indeed, the main search procedure can be written in less than 30 lines of C-code. It is easy to use as it needs only two control parameters that can be chosen from well defined numerical intervals. A theoretical convergence proof for DEM is still missing. As shown in the simulation studies, DEM successfully solves the parameter estimation problem of neural spatial interaction models. A comparison with multistart of conjugate gradients illustrates that DEM outperforms the benchmark in terms of out-of-sample performance, when the computing time limit is high (approximately 1 h 30 min on PC Pentium 400 Mhz [55 min on DEC Alpha 375 Mhz] for one trial).
The method lends itself for further development in the field of spatial interaction modelling and might be useful for other non-linear optimization problems in GeoComputation and regional science as well.
The authors gratefully acknowledge grant no. P12681-INF provided by the Fonds zur Foerderung der wissenschaftlichen Forschung (FWF).
Diplock G.J., 1996. Building new spatial interaction models using genetic programming and a supercomputer. Paper presented at the First International Conference on GeoComputation, Leeds, September 17-19, 1996 [available from the School of Geography, University of Leeds, Leeds LS29JT, U.K.].
Duch, W. and J. Korczak, 1998. Optimization and global minimization methods suitable for neural networks. Neural Computing Surveys 2.
Fischer, M.M., 1998. Computational neural networks: A new paradigm for spatial analysis. Environment and Planning A 30(10), pp. 1,873-91.
Fischer, M.M. and S. Gopal, 1994. Artificial neural networks: A new approach to modelling interregional telecommunication flows. Journal of Regional Science 34 (4), pp. 503-27.
Fischer, M.M. and Y. Leung, 1998. A genetic algorithm-based evolutionary computational neural network for modelling spatial interaction data. The Annals of Regional Science 32(3), pp. 437-58.
Fischer, M.M. and P. Staufer, 1999. Optimization in an error back-propagation neural network environment with a performance test on a spectral pattern classification problem. Geographical Analysis 31(2) (in press).
Fischer, M.M., K. Hlavackova-Schindler and M. Reismann, 1999. A global search procedure for parameter estimation in neural spatial interaction modelling. Papers in Regional Science 78 (in press).
A.S. Fotheringham, 1983. A new set of spatial interaction models: The theory of competing destinations. Environment and Planning A 15, pp. 15-36.
Goldberg, D., 1989. Genetic Algorithms in Search, Optimization, and Machine Learning. Reading (MA), Addison-Wesley.
Gopal, S. and M.M. Fischer, 1996. Learning in single hidden-layer feed-forward network models: Back propagation in a spatial interaction modelling context. Geographical Analysis 28(1), pp. 38-55.
Hornik, K., M. Stinchcombe and H. White, 1989. Multilayer feed-forward networks are universal approximators. Neural Networks 2, pp. 359-66.
Openshaw, S., 1988. Building an automated modelling system to explore a universe of spatial interaction models. Geographical Analysis 20(1), pp. 31-46.
Openshaw, S., 1993. Modelling spatial interaction using a neural net, In Geographical Information Systems, Spatial Modelling, and Policy Evaluation, Eds. M.M. Fischer and P. Nijkamp, Berlin, Springer, pp. 147-164.
Press, W.H., S.A. Teukolsky, W.T. Vetterling and B.P. Flannery, 1992. Numerical Recipes in C. The Art of Scientific Computing. Cambridge, England: Cambridge University Press.
Storn, R. and K. Price, 1996. Minimizing the real functions of the ICEC '96 contest by differential evolution, IEEE Conference on Evolutionary Computation, Nagoya, pp. 842-44.
Storn, R. and K. Price, 1997. Differential evolution - a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization 11, pp. 341-59.
Turton, I., S. Openshaw and G.J. Diplock, 1997. A genetic programming approach to building a new spatial model relevant to GIS, Innovations in GIS 4, Ed., Z. Kemp. London, Taylor & Francis, pp. 89-102.
Wilson, A.G., 1970. Entropy in Urban and Regional Modelling. London, Pion.