|
1
|
|
|
2
|
- 1. Introduction
- 2. Grids 1.0
- 3. Example outputs
- 4. Further work
|
|
3
|
|
|
4
|
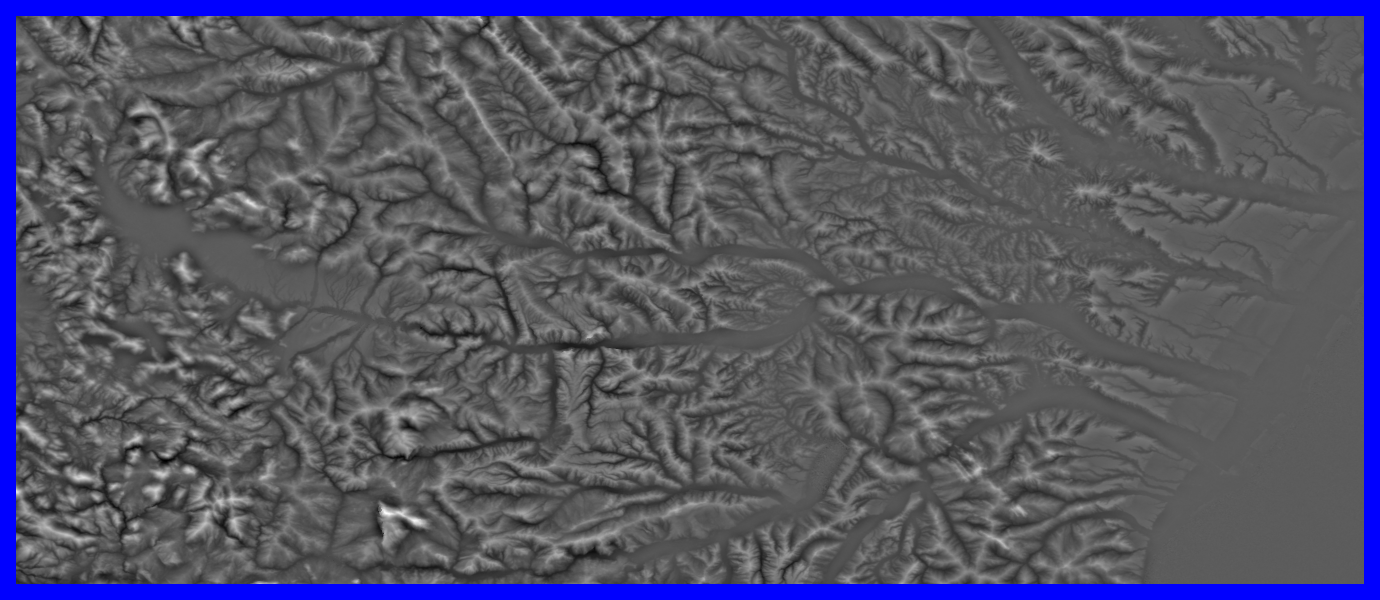
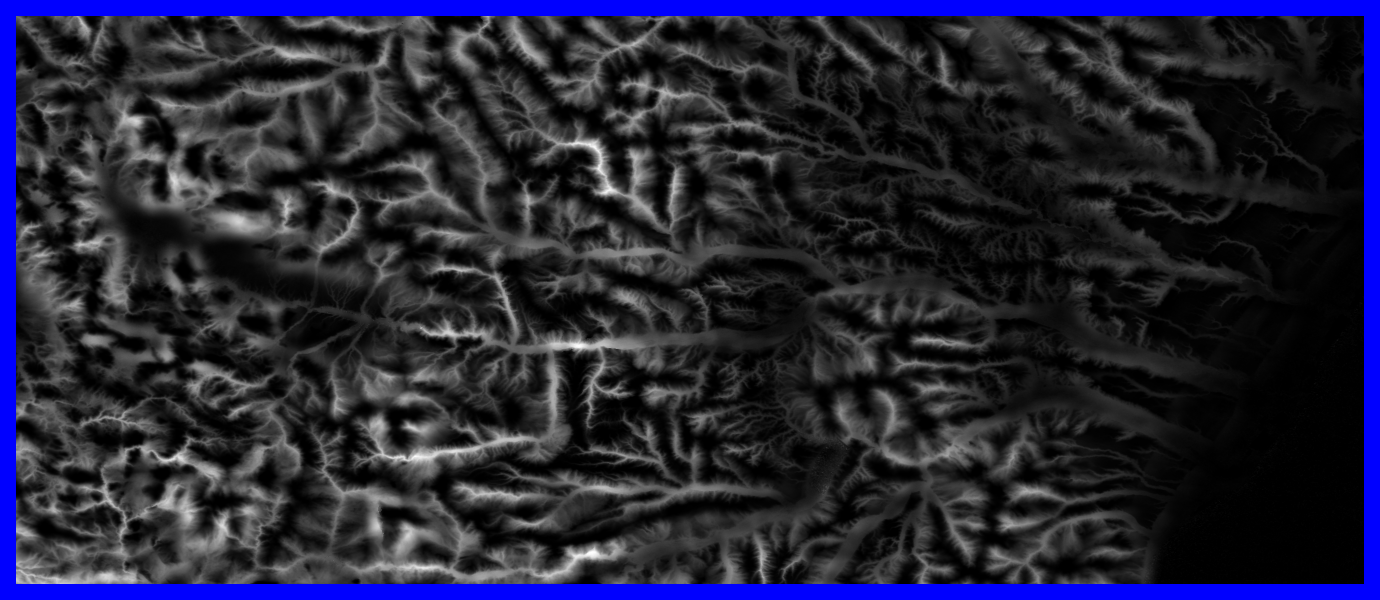
- Projected from Lat/Lon 3 arc second resolution grid into a Lambert
Azimuthal Equal Area projection
- Ncols 49724
- Nrows 16373
- Cellsize 82.4544
|
|
5
|
|
|
6
|
- From 60° North to 60° South
- Ncols 432000
- Nrows 220800
- Cellsize 3 / 60 / 60 (3 arc seconds)
|
|
7
|
- SRTM DEM data is being produced at a 1 arc second resolution
- North America is available
- Soon after we will have higher resolution…
- We have 10 meter resolution DEM for the UK…
- Again hundreds of thousands of rows and columns
- Soon we will have more higher spatial resolution
|
|
8
|
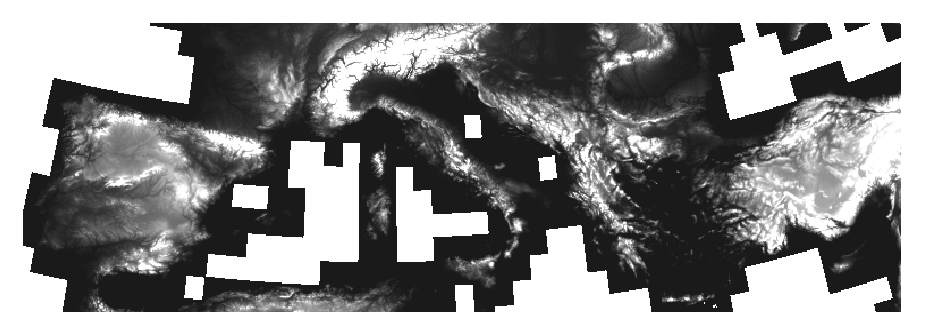
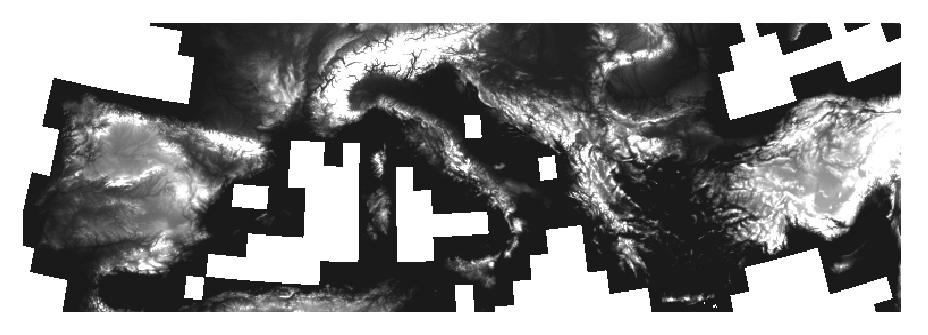
- DesertLinks and tempQsim
- Need to focus on processing European - especially the Mediterranean
region of the European Union
- Hydrological DEMs
- Hydrological variables
- Flow accumulation
- Wetness index
- Geomorphometrics
- Physical indicators
- Salinity and Erosion risks
- Based on 3 arc second SRTM data
- We want something much better than HYDRO1K and ArcGIS9
|
|
9
|
|
|
10
|
- There are 4 packages:
- core
- exchange
- process
- utilities
|
|
11
|
- So what are geomorphometrics?
- Measures of the state and change in surface geometry of earth’s
physical horizons
- Topographic measures
- Terrain analysis aids
- Spatial variables
- Components of desertification indexes?
|
|
12
|
- Grids
- Basic unit is a cell
- A value attributed to a point of a lattice that covers a 2D plane
- double
- int
- Basic arrangement
- Chunks of cells arranged in rows and columns
- Chunk are rectangular and a fixed size for a grid
|
|
13
|
- No chunk may contain more than java.lang.Integer.MAX_VALUE (2147483647)
number of rows or columns
- There can also be no more than java.lang.Integer.MAX_VALUE number of rows
or columns of chunks
- Need further testing to specify exactly
|
|
14
|
- Advantages
- each chunk can be stored optimally using any of a number of data
structures; and,
- each chunk can be readily cached and re-loaded as needs be
- Lightweight, but some overhead
- The usual practice is to use chunks that are relatively small but larger
than 64 cells
|
|
15
|
- 64CellMap
- 2DArray
- JAI
- Map
- RAF
|
|
16
|
- The most sophisticated data structure?
- Data stored in a fast, lightweight implementation of the java.util
Collections API
- gnu.trove
- TdoublelongHashMap
- TintlongHashMap
- The long is gives the mapping of the value to the 64 cells in the chunk
|
|
17
|
- for chunks that contain a single cell value there is a single mapping in
the HashMap
- for chunks with 64 different cell values there are 64 mappings in the
HashMap
- Iterating over (going through) the keys in the HashMap is necessary to
get and set cell values, so generally this works faster for smaller
numbers of mappings.
|
|
18
|
- A mapping of keys (cell values) and values (cell identifiers) is a
general way of storing grid data.
- Efficient in terms of memory use where a default value can be set, and
if there are only a small number of non-default mappings in the chunk
(compared to the number of cells in the chunk)
- Offer the means to generating some statistics about a chunk very
efficiently
- the diversity (number of different values)
- mode
|
|
19
|
- Each chunk and grid is associated with a factory and an iterator
- Factories keep things tidy, production can be done in one place and an a
controlled way
- Iterators offer the fastest and most efficient way of going through all
the values in a grid or chunk
- These can be ordered and unordered
|
|
20
|
- Attached to every grid is a statistics object
- Implemented by every statistics object and every chunk and grid is a
statistics interface
- Abstract classes provide a generic way of returning statistics
- Specific chunks and grids can override these methods to provide faster
implementations
|
|
21
|
- Two basic types attached to a grid
- Updated
- Statistics initialised and kept up to date as underlying data changes
- Better if statistics are wanted
- Not updated
- Statistics not initialised or kept up to date as underlying data
changes
- Better is statistics are not wanted
|
|
22
|
- nonNoDataValueCountBigInteger
- number of cells with non noDataValues
- sumBigDecimal
- the sum of all non noDataValues
- minBigDecimal
- the minimum of all non noDataValues
- minCountBigInteger
- the number of min values as a BigInteger
- maxBigDecimal
- the maximum of all non noDataValues
|
|
23
|
- /**
- * This method does something
- * @param args an Object[]
containing the arguments needed for processing
- * @param handleOutOfMemoryError
If true then OutOfMemoryErrors are caught
- * in this method then caching
operations are initiated prior to retrying.
- * If false then OutOfMemoryErrors are
caught and thrown.
- */
- public Object[] methodToProcessl( Object[] args, boolean
handleOutOfMemoryError ) {
- try {
- return
anotherMethodToProcess( args, handleOutOfMemoryErrorFalse );
- } catch (
java.lang.OutOfMemoryError oome0 ) {
- if ( handleOutOfMemoryError
) {
- clearMemoryReserve();
- clearChunk( cacheChunk()
);
- initMemoryReserve();
- return methodToProcessl(
args, handleOutOfMemoryError );
- } else {
- throw oome0;
- }
- }
- }
|
|
24
|
- Want to avoid trying to free up memory by caching a chunk that is needed
- methods to stop this happening
- cacheChunksExcept( ChunkID[] chunks )
- When processing there can be multiple grids and it might be better to
cache coincident chunks, rather than all chunks in one grid then the
next etc…
|
|
25
|
- 3 classes
- processor
- GWS extension
- DEM extension
- Logging
- Memory handling
- Workspace
- Methods
- addToGrid
- aggregation
- value replacement
- arithmetic operators
- rescaling
|
|
26
|
- Weighting
- Normalisation
- Cross scale
- 2 main types:
- Univariate
- First order
- Second order
- moments (proportions, variance, skewness)
- Bivariate
- difference
- normalized difference
- correlation
|
|
27
|
- Methods
- Hollow or pit detection
- Hollow filling
- Flow accumulation
- Distributive
- Based on all downslope cells not just maximum
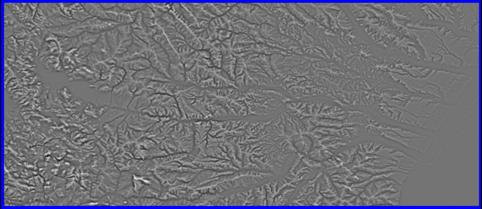
- Geomorphometrics
- E.g. Slope and aspect
- Regional based and weighted like GWS
|
|
28
|
|
|
29
|
|
|
30
|
- Slope is the gradient and aspect is the angle to a particular
orientation over a given region
- Circular region
- Vector addition
- Distance weighting
- Scales
|
|
31
|
|
|
32
|
|
|
33
|
|
|
34
|
|
|
35
|
|
|
36
|
|
|
37
|
|
|
38
|
|
|
39
|
|
|
40
|
- Differencing to focus on mid-scales can be done directly by applying a
more complex spatial weighting scheme
- Only relevant for some measures
- Not aspect
- What about upness and downness?
|
|
41
|
|
|
42
|
|
|
43
|
|
|
44
|
- Rotation invariant metrics
- Axis based metrics
|
|
45
|
- For each metric compare each orthogonal set within a region
- What do is observed?
- hhhh, hhhl, hhll, hlhl, hlll, llll
- Based on this observation we add to particular metrics
- Conditioners
- max, min, sum (and absolute variants)
|
|
46
|
- How to treat cells with the same height?
- How to treat cells with no data value?
- What conditioners are appropriate?
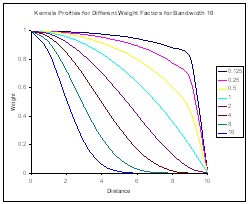
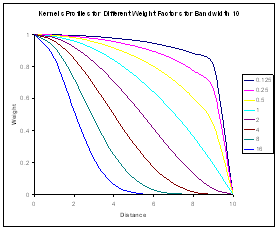
- Two types of weight
- Distance weighting
- Difference in elevation weighting
- What is best?
|
|
47
|
|
|
48
|
|
|
49
|
|
|
50
|
|
|
51
|
- Profile or Contour
- Concavity or Convexity
- Convergence or Divergence
|
|
52
|
- What other interesting metrics?
- minimum type profile concavity
- maximum type profile convexity
- Better for identifying features?
- Probably best in combination with the other metrics
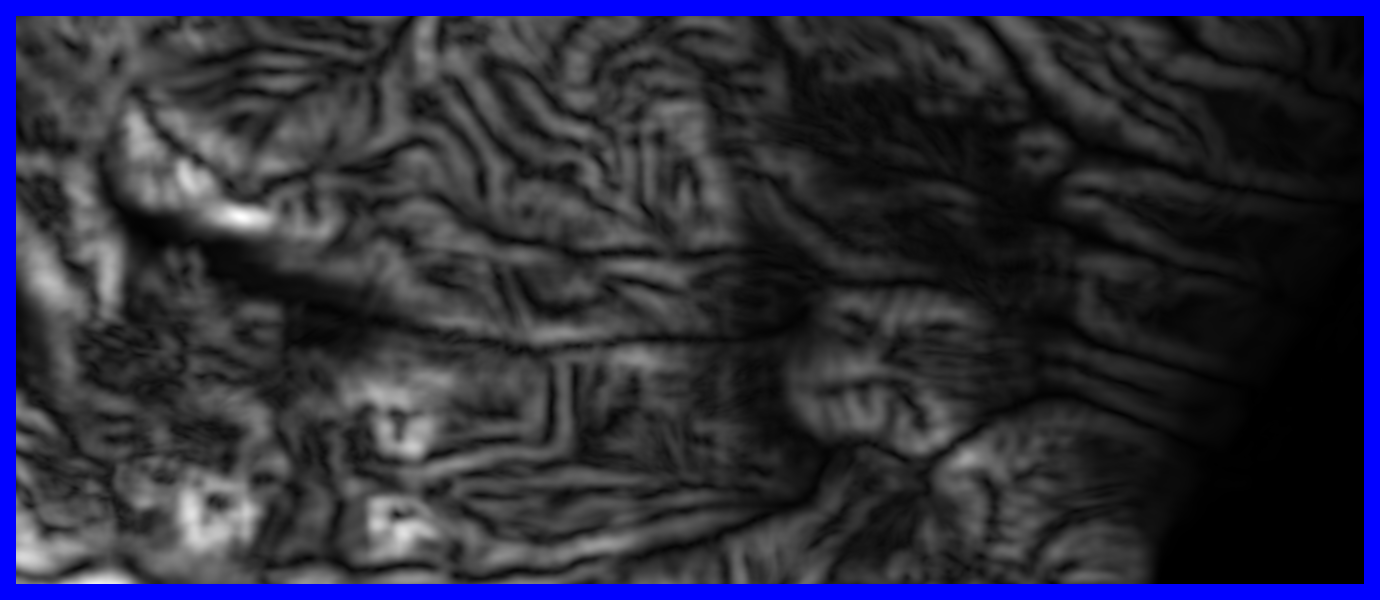
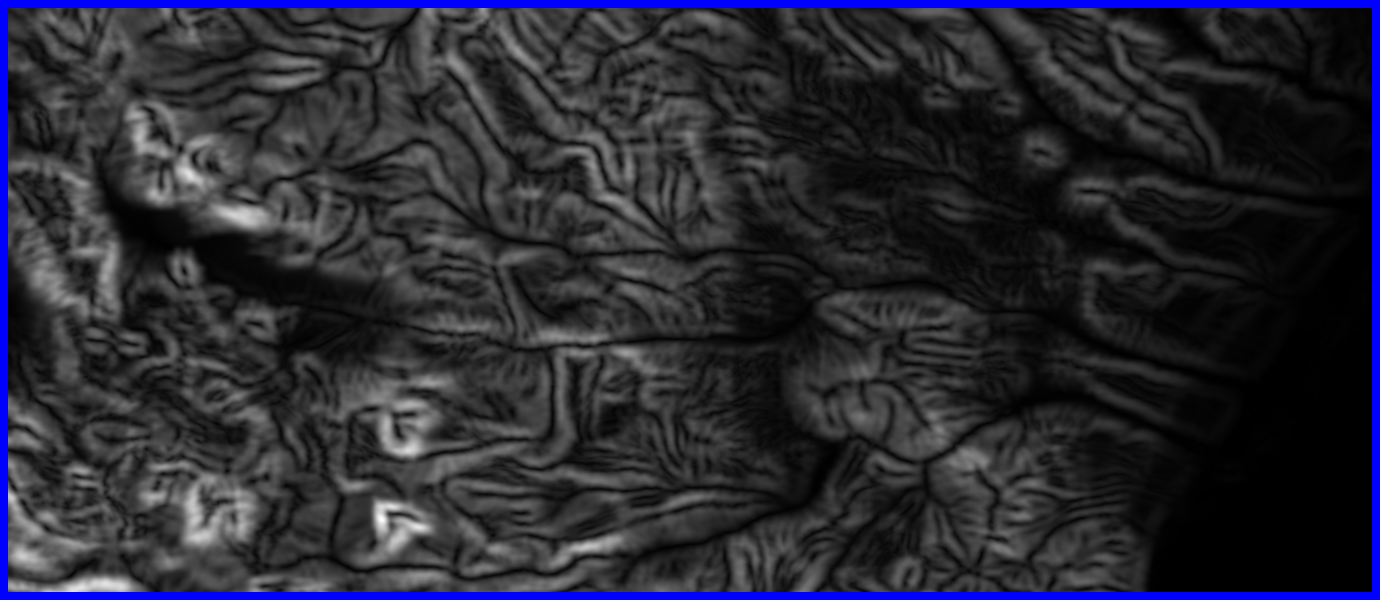
- Sorry, no examples!
|
|
53
|
- Release Grids 1.0
- Organise the development of grids as an open source project
- Potentially integration with GeoTools
- Provide examples for the Mediterranean
- Get other users to play around and analyse output
- Compare functionality with respect to proprietary GIS outputs
|
|
54
|
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}