2. ESDA, data mining and spatial data mining tools
To recap, spatial data mining systems are essentially ESDA tools.Ā ESDA and spatial data mining involve an interactive search for patterns or regularities in spatial data.Ā The processes could begin by visualising data in maps, graphs, charts, plots and tables.Ā Following this some form of data classification and some form of variable prediction could be performed, the results visualised and the predictions and models tested in some way.Ā This process could continue until something interesting or useful emerged or until the analyst became satisfied that the data contained no detectable patterns of interest.
Vastly increasing quantities of spatially referenced data of all kinds are being collected all the time, much of it relates to geographical and geophysical processes and much of it is of public interest.Ā This has led to data rich but theory poor environments that fundamentally require an exploratory rather than a confirmatory hypothesis driven approach.Ā Tools needed to help generalise and visualise patterns in these data have begun to emerge, but tools that use all the available data at the highest level of resolution with a minimum of preselection as yet have not.
ESDA tools, in particular SPIN, should be designed to be end-user friendly in that the results should be understandable and capable of being safely used by people who do not have higher degrees in the statistical or spatial sciences.Ā Outputs from the tools should aim to stimulate the imagination.Ā If there are patterns hidden in spatial data or indeed relationships encrypted in spatial information then the ESDA tools in SPIN should help users to find them by at least pointing them in the right direction.Ā An important goal is to provide an end-user friendly ESDA environment containing highly automated analysis tools that are easy to apply, whose visualised outputs are easy to interpret and whose techniques are explained in simple terms so that non-experts can understand how they work.
It is important to appreciate the vast difference between exploring a manageable small data set with few variables and the need to perform the same process on massive databases (with many more cases) and possibly high levels of multivariate complexity.Ā Manual graphical exploration of multi dimensional spatio-temporal data does not scale well, that is, the larger the volume of data gets - the greater is the need for generalisation and automated analysis methods.
There are a number of data mining tools designed to assist the process of exploring large amounts of data in search of recurrent patterns and relationships.Ā Many developers and users of these tools appear to believe that their tools will work with any and all data regardless of its subject origins.Ā This overlooks the features of geographical information that make it special that were summarised above in Table 1.Ā GDM is a special type of data mining that has to take into account the special features of geographical information, the rather different styles and needs of analysis and modelling relevant to the world of GIS, and the peculiar nature of geographical explanation.
It can be argued that conventional data mining tools are still useful, in the same way that conventional statistical methods can be applied to spatial data.Ā However, the view expressed here is that conventional statistical techniques and conventional data mining tools are not sufficiently focused on, and tailored to, the special needs of geographical analysis today.Ā Most data mining packages offer: exploratory data analysis tools to display data in various ways; most multivariate statistical methods including linear and logistic regression; various classification and modelling tools, such as decision trees, rule induction methods, neural networks, memory or case based reasoning; and, sequence discovery (time series analysis).Ā Many of these methods can be usefully applied to spatial data.Ā For example, data reduction tools, such as multivariate classification, can be useful as a means of summarising the essential features of large spatial data sets.Ā Modelling tools such as neural networks and decision tees can be readily applied to some geographic problems.Ā Although it can be argued that these methods ignore some of the special features of geographical information outlined in Table 1 - they can still be usefully applied to spatial data.
Conventional DMS have no mechanism for handling location or spatial aggregation or for coping with spatial entities or spatial concepts such as a region or circle or distance or map topology.Ā What are therefor needed are new types of data mining tools that can handle the special nature of spatial information.
Most analytical functionality available in DMS are simple extensions and generalisations of techniques used for decades. The core functionality in most DMS is based on artificial intelligence and other techniques that can be set to search for patterns and trends in large volumes of data.Ā Neural networks (NN) are universal approximators that mimic the workings of animal nervous systems that learn to classify and generalise patterns in their local environments.Ā They have powerful pattern recognition and generalisation capabilities derived from their ability to learn to represent complex multi-variate data patterns.Ā There are three main types of neural network commonly used in research; the multilayer perceptron, the learning vector quantisation network, and the self organising map.Ā Multilayer perceptrons are perhaps the most common, but the majority of DMS also incorporate some form of self organising map.Ā Genetic algorithms (GA), also called evolutionary algorithms, constitut a set of powerful global search heuristics that are also biologically inspired.Ā They mimic the basic idea of the evolution of life forms as they adapt to their local environments over many generations.Ā Both NN and GA provide a means of approaching highly complex search problems by simulating in the computer the biological process of natural selection and we should aim to incorporate them in SPIN.
Clementine
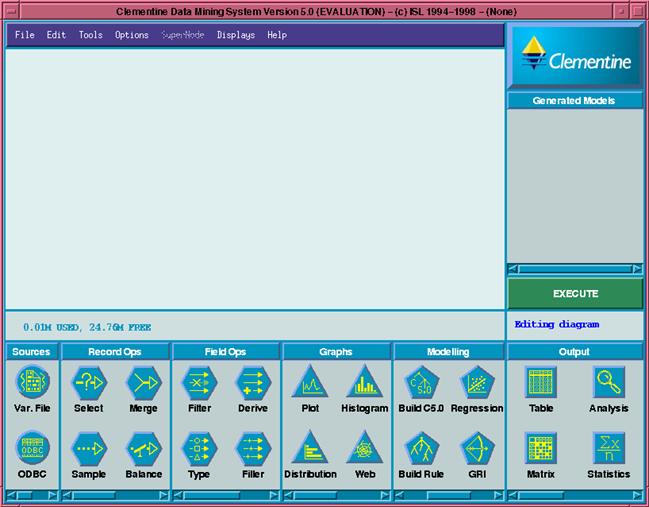
Clementine Data Mining System (Clementine) was originally developed by Integral Solutions Ltd who were recently bought by SPSS.Ā SPSS offer various training courses, provide a support service for users of Clementine and undertake consultancy work.Ā Clementine has a user friendly visual programming GUI for developing data mining applications, see Figure 1 below.Ā There is a menu across the top which can be used to load and save features specific to the data mining application, set parameters, run modelling scripts and load a basic help system.
Clementine stores input data as a table and most operations are performed sequentially record by record.Ā The skeleton of a data mining application is represented by a set of stream diagrams which are usually constructed in the GUI model building pallet but can also be defined using CLEM, the Clementine macro modelling and scripting language.Ā Streams can be saved and loaded from file and can be executed more efficiently in batch mode using modelling scripts.Ā All Clementine streams are comprised of a set of nodes which are linked together to form a sequence of operations on a table of data.Ā A variety of nodes can be selected from the node pallet at the bottom of the GUI and connected into a stream, the following types of node are available:
- Source nodes: These are used to define the input data and read it into a table.
- Manipulation nodes: These are either used to perform operations on records (rows of data) or on fields (columns of data).Ā They are used to define the field type, derive new fields, filter out unwanted fields, join or merge tables together, select records, append records, sample records, sort records, or balance records (by either generating or deleting records under specific criteria).Ā (Whether operating on rows or columns of a table, data is read record by record, so in general field operations are far less efficient than record operations.)
- Graph nodes: These are visual display including histograms, bar charts, point or line plots and web diagrams.
- Modelling nodes: These include; a train_net_node from which 5 different types of supervised neural networks can be specified, a train_kohonen_node to perform unsupervised classification into a specified number of classes using the Kohonen self organising map (SOM), a train_kmeans node to perform Kmeans classification, a simple linear regression node and four different types of build rule nodes which either produce decision trees or association rule sets.
- Generated model nodes: These are the models generated upon execution of a modelling node.
- Output nodes: These include a node for calculating summary statistics and the correlation between specified variables, a node for generating standard output files, a node for creating a matrix output, a node for analysing the fit of a model, and a node for setting global parameters for a stream.
- Supernodes: These are parts of a stream catenated into a single icon for which internal parameters can be set. Streams that split into multiple streams cannot be encapsulated in a supernode.
A useful feature, particularly for streams that split into multiple channels, is that as the data table passes through a node it can be cached (stored at that node).Ā Nodes, streams, caches, generated models and modelling scripts can be individually saved and loaded from file as can the state of any Clementine session which stores the stream, any generated models, current parameter values and the modelling script associated with the stream.Ā Clementine has several types of parameter including slot parameters, supernode parameters, stream parameters and global parameters.Ā Slot parameters are used to control some of the editable characteristics of nodes, whereas, supernode parameters, stream parameters and global parameters are more like declared variables used in conventional programming.Ā A major limitation of the system is that data or parameter values cannot be passed back to a modelling script from the stream it is executing.Ā This means that Clementine cannot automatically perform many potentially ver useful recursive operations.Ā First impressions of Clementine are that the GUI is tidy, elegant and intuitively laid out, but its data manipulation functionality and visualisation capability are basic.Ā For more information on Clementine refer to SPSS.
Figure 1. Clementine GUI
Intelligent Miner
The IBM intelligent miner for data (IMiner) is described by IBM as: ō... a suite of statistical, processing, and mining functions that you can use to analyse large databases.Ā It also provides visualisation tools for viewing and interpreting mining resultsģö IMiner provides access to on-line analytical processing functions for cleaning and re-arranging data in a similar way to the data manipulation nodes provided in Clementine.Ā These processing functions enable missing values to be defined, rows and columns of data to be filtered, data to be discretised into specific ranges, randomly sampled, aggregated, joined, and converted to lower or uppercase.Ā IMiner enables you to specify cyclic fields where values have a cyclical relationship to each other such as days of the week.Ā IMiner can also create taxonomy objects to define a hierarchy of relations between data categories.Ā Each item of a data table can be categorised and corresponding relations between these item categories can be used to define associations and sequential patterns.
The standard statistical functions available include bivariate statistics, factor analysis, linear regression, principle component analysis, and univariate curve fitting.Ā The following IMiner data mining functions are available:
- Associations mining function - designed to reveal associations that one set of items in a transaction implies about other items in that transaction (where a transaction is a row of a data table).
- Sequential patterns function - designed to discover patterns over time.
- Tree induction - a binary decision tree based on the SLIQ algorithm that can handle both numerical and categorical data attributes.
- Neural classification and prediction - these are either radial basis function nets or standard multi-layer perceptron type neural nets capable of supervised training using a back propagation algorithm.Ā These create sensitivity analysis reports that rank the input fields according to the degree of relevance or accuracy to the resulting classification or prediction.
- Neural clustering - this is a Kohonen net or self organising map (SOM) classifier which is a neural network in which the neurons iteratively compete to represent the data classifying it into clusters.
- Demographic clustering - this is similar to Kmeans but slightly more sophisticated in that the user can weight specific fields or values and can treat outliers in a number of different ways.
These functions have been developed to exploit RS/6000 SP hardware (configured by IBM) and use parallel DB2 software (licensed by IBM).Ā For more information on IMiner refer to IBM.
The functionality of Clementine and IMiner are almost identical.Ā Clementine has a nicer interface and is better in terms of visualisation, but is slower.
GeoMiner
GeoMiner claims to be a knowledge discovery system for spatial databases and GIS.Ā It is software implemented on a MapInfo proprietary GIS platform with access to on-line analytical processing functionality.Ā The available information regarding GeoMiner is hyped up containing exaggerated claims about its capabilities.Ā The functionality of the system is described using simple examples of the sorts of analysis that can be done with it.Ā The main spatial data mining operations are referred to as drill down and roll up.Ā Drill down is the process of examining data and mining results at higher general levels of spatial resolution, and roll up is the reverse process, which involves aggregating and generalising data and mining results at coarser levels of spatial resolution.
The GeoMiner functions include a geo-characterizer, a geo-comparator, a geo-classifier, a geo-associator, and a geo-cluster analyzer.Ā The geo-characterizer module is for finding æa set of characteristic rules at multiple levels of abstractionÆ.Ā Applying this module involves selecting and retrieving a subset of data from the database using some form of query.Ā Then some form of spatial aggregation is performed to group data into larger user defined regions.Ā Selected aspatial data variables are then analysed for each region using what is called the æattribute-oriented induction techniqueÆ.Ā The geo-comparator module is for defining a set of comparison rules, which contrast the general features of different classes of the relevant sets of data in a database.Ā This compares one set of data, known as the target class, to other sets of data, known as contrasting classes.Ā The geo-associator module is said to find a æset of strong spatial-related association rulesÆ.Ā A typical spatial association rule is in th form of IF A THEN B (s%, c%) where A and B are sets of spatial or nonspatial predicates, s is the support of the rule (the probability that A and B hold together among all the possible cases), and c is the confidence of the rule (the conditional probability that B is true under the condition of A).Ā This functionality is already proposed for SPIN.Ā Mining spatial association rules is similar to the process of analysing aspatial association rules.Ā The geo-cluster analyzer module is for finding clusters of points with relevant aspatial attributes.Ā It uses an algorithm called CLARANS to perform spatial clustering.Ā Basically, the spatial clustering module involves drawing a user defined number of convex polygons to represent spatial clusters of point data.Ā Analysis can then be done by generalising and comparing the point attributes of the polygons.Ā Additional analysis might involve repeating this for different expected numbers of clusters and examining differences between the polygons.Ā The geo-classifier moule uses a decision-tree induction method to classify a set of relevant data according to one of the aspatial attributes. The classification tree is then displayed and by clicking on any of the nodes of it a user can highlight corresponding regions on a linked map.
The GeoMiner system although limited in some ways does enhance ESDA capablities.Ā For a more comprehensive review of the functionality in GeoMiner refer to SPIN!-report D3 from Work Package 3.
3. SAGE, LiveMap, CDV, GeoTools and GeoVista
SAGE
SAGE is a spatial statistical analysis environment for interactively studying area-based data.Ā It is based on the ArcInfo GIS developed by ESRI and provides some spatial statistical functionality and a linked display environment.Ā The GUI contains a single map view, a table and one or more graphical representations of the data including histograms, scatterplots, rankit plots, boxplots, lagged plots and matrix graphs.Ā Rankit plots are effectively scatterplots of a variable against its Z-scores.Ā Lagged plots are a series of boxplots for a variable where (for a selected area) the ith-boxplot corresponds to the values of that variable in the ith-order adjacent areas.Ā SAGE contains tools for creating these displays, for calculating basic statistics, for fitting regression models and for regionalising data.Ā Data can be selected and queried from the maps and tables and new variables can be defined using basic arithmetic expressions.Ā SAGE creates various n by n weights matrices when area data is loaded, (where n is the number of areas in the data set).Ā One contains adjacency information, so if ni is adjacent to nj then nij=1 else nij=0; another stores the distance between the area centroids; and the other stores the length of the shared boundary between adjacent areas.Ā The matrices are used to create regionalisations and ith-order adjacency information.Ā One of the most useful features in SAGE is the ability to create statistics on the ith-order adjacencies and it is worth considering the incorporation of such functionality in SPIN.Ā For more information see Jingsheng et.al. (1997) available at the following URL:
ftp://ftp.shef.ac.uk/pub/uni/academic/D-H/g/sage/sagehtm/sage.htm
LiveMap
LiveMap is a spatial statistical tool conceived for ESDA.Ā It is Lisp programming code that adds some map drawing functions to Xlisp-Stat which is a statistical programming environment that enables new statistical techniques to be developed easily and analysis to be performed ad hoc.Ā It does not provide a GUI to a toolkit of commonly used techniques, rather it provides a command line from which interactive graphics and a vast range of statistical techniques can be called with Lisp protocols. The linked display environment and the ease of producing maps and other graphical output aims to encourage users to adopt an exploratory and graphical approach.Ā To really take advantage of LiveMap and extend and customise the system for a particular application a user must become very familiar with the Lisp language and what Xlisp-Stat has to offer in terms of available statistical functionality, (detail of this functionality is not covered here although some of it is outlined in the Section 5).Ā The available XLisp-Stat functionality is extremely diverse and the command line environment makes them all equally accessible and applicable to spatial data once the syntacs of the command is understood.Ā The most notable feature of LiveMap is its ability to link multiple maps and graphical displays.Ā Extensive documentation including examples of the use of the software and a thorough help system are also very attractive features of LiveMap that enable it to be picked up and applied fairly easily by users with intermediate level statistical skills and a basic programming ability, see Brunsdon (1998).Ā LiveMap is a good example of a state of the art exploratory spatial statistical environment providing a linked display environment, which has become a common feature of ESDA environments and is rightly a core component of SPIN.Ā More detailed information about Livemap is available at the following URL:
http://www.stat.ucla.edu/xlisp-stat/code/incoming/
CDV
CDV is a cartographic data visualiser that demonstrates the utility of linked display ESDA environments.Ā It is based on a GUI that is visually impressive and highly responsive in its display of GIS data.Ā It is a demonstration tool that promotes dynamic linked display environments as ESDA tools.Ā It permits numerous linked views containing a number of plots including; box-plots, scatter-plots, polygon maps, graduated circle maps, population cartograms and parallel coordinates plots.Ā Symbols in each view are dynamically linked to corresponding cases in all other views and new views can be created from subsets selected from any view.Ā There is a calculation function that provides an equation parser so as to derive variables using basic mathematical functions.Ā CDV as a demonstration provides the look and feel that SPIN is aiming for.Ā The cartogram display functionality is a particularly novel feature that SPIN should consider including.Ā For more information on CDV refer to Dykes (1997) and the following RL:
http://www.geog.le.ac.uk/jad7/cdv/release/Documents
GeoTools and GeoVista
GeoTools is an open source Java based mapping toolkit that is designed for viewing maps interactively on web browsers without the need for dedicated server side support.Ā Geotools has provided a stable framework for producing the types of facilities available in CDV in a portable scalable and distributed manner.Ā The functionality of GeoTools and the fact it is written in Java make it a useful reference for what we are trying to achieve.Ā The latest version of GeoTools and further information is always available from the following URL:
http://www.ccg.leeds.ac.uk/geotools
GeoVista studio is another open source Java application.Ā It visualises parallel coordinates plots and Self Organising Maps and has a bean architecture which offers a coordinated way of designing linked displays and GUIs.Ā There is a plan to make GeoTools into a bean so it can be directly plugged into GeoVista studio to add mapping functionality.Ā This development is new and little information is available but it will be posted either on the GeoTools web site or at the following URL:
http://www.geovista.psu.edu
4. Fuzzy logic
Fuzzy logic and fuzzy set theory resemble human reasoning in that it deals with approximate information and uncertainty to generate decisions.Ā Fuzzy logic is a superset of Boolean logic where everything is either true or false.Ā In fuzzy logic things are both true to a degree and false to another degree.Ā In the same way fuzzy set theory is a superset of conventional set theory, the difference is that fuzzy set theory does not conform to the law of the excluded middle.Ā In other words, fuzzy set theory allows each element of a set to also belong to its compliment to a relative degree.
Most spatial data is fuzzy, imprecise and vague.Ā Any methodology or theory implementing precise definitions such as classical set theory, arithmetic, and programming, may be fuzzified by generalising the concept of a crisp set to a fuzzy set.Ā Fuzzy logic, fuzzy set theory and fuzzy inference are very useful in attempts to solve data modelling and control problems involving imprecision and noise in the data and information used.
Fuzzy logic allows for constructingĀ linguistic variables that enable computation to be done with linguistic IF THEN ELSE statements, such as, if road density is high and population density is low then non-road land use nearby is more likely to be business or commercial than residential else there are a fairly large number of empty or partially populated dwellings.Ā Terms such a 'large' 'medium' and 'small' are defined using membership functions where values can have varying degrees of belonging or membership to each group.Ā Fuzzy set theory encompasses fuzzy logic, fuzzy arithmetic, fuzzy mathematical programming, fuzzy topology, fuzzy graph theory, and fuzzy data analysis, though the term fuzzy logic is often used to describe them all.
Because fuzzy logic can handle approximate information in a systematic way, it is ideal for controlling nonlinear systems and for modelling complex systems.Ā A typical fuzzy system consists of a rule base, membership functions, and an inference procedure.Ā Developing a fuzzy logic component in SPIN could be extremely useful.Ā Details on the vast range of fuzzy software available can be found on the Web at the following URLs:
STATS: SpaceStat, S+, and GWR
Statistics is the theory of accumulating information that attempts to answer three basic questions:
- How should data be collected?
- How should data be analysed and summarised?
- How accurate are the data summaries?
The third question concerns part of the process known as statistical inference (SI).Ā Regression, correlation, analysis of variance, discriminant analysis, standard error, significance levels, hypothesis testing, probablility distributions, expectations, confidence intervals, random sampling and the bootstrap are all part of SI.Ā Probability theory provides the mathematical framework for SI.Ā SI concerns learning from experience based on samples and often involves estimating some aspect of a probability distribution such as a maximum likelihood.
SpaceStat
SpaceStat provides standard statistical functionality for calculating the mean, range, variance, standard deviation, skewness and kurtosis of a variable.Ā It provides functionality for measuring how close the distribution of variable values is to a normal distribution and provides a way of calculating Pearson's correlation coefficient and principle components.Ā Seemingly more relevant for spatial data is its functionality for calculating multivariate spatial correlation and spatial principle components.Ā Multivariate spatial correlation first involves standardising all values of every variable by taking away the mean value of the variable and dividing by its standard deviation.Ā These standardised values are then stored in a matrix S (where the columns are the variables and the observations are the rows) which is transformed by a stochastic (where all elements sum to 1) spatial weights matrix W by using the following matrix equation:
T = STWS where ST is the transpose of S
The values of the elements in the matrix T and its eigenvalues and eigenvectors can be analysed to gain some idea of spatial associations between variable values.Ā This interpretation is far from easy, but a basic comparison with aspatial principal components can provide a useful means of identifying spatial effects although it is difficult to infer much about them.Ā The simplest measures of spatial autocorrelation SpaceStat provides are join count statistics.Ā These simply count the number of joins between areas of one class and areas of another class.Ā SpaceStat is restricted to using binary classes, however the method is useful and can be extended to handle fuzziness by using continuous values, multiple sets, and ith-order contiguity data and as such should be considered for SPIN.Ā SpaceStat can also be used to calculate Moran's I and Geary's C statistics which provide some indication of the nature (positive or negative) of spatial autocorrelation.Ā The magnitude of these statistics is har to interpret.Ā Further inference can be attempted by assuming normality or randomness in the distribution of permutations (created by omitting observations) of these statistics then testing the assumption by detecting significant differences of the observed values from theoretically expected ones.Ā Some way of omitting observations based on spatial criteria may be useful in detecting spatial effects in such inference, however, this is all very statistically intricate and the non-normality or non-random assumptions are inherently flawed.Ā Like most statistics or mathematical formulae applied to spatial data, both Moran's I and Geary's C statistics are best applied to different and possibly overlapping sets of localities and then analysed in terms of the differences or variations between the spatial subsets.Ā Unless spatial subsets or localities are used the statistics are global providing little useful spatial information that is not highly sensitive to the problem of modifiable areal units.Ā When applied in localities, such statistics are termed local indicators of spatial association (LISA).Ā SpaceStat does not provide functionality that makes this easy, but it does have the building blocks required for it.Ā Providing the functionality for applying a range of statistics for different types of strictly tessellating and overlapping spatial subsets is something worth considering for SPIN.Ā For more information on Spacestat refer to Anselin (1992), Anselin (1995) and the following URL:
http://www.spacestat.com/
S+
S+ is a widely used flexible package and programming language for statistical research.Ā Two official S+ extensions that have appeared in recent years are S+SpatialStats and S+ArcView.Ā These are specifically geared for use by geographers and the like who need to analyse spatial data. S+SpatialStats offers a variety of graphical display functionality of interest for ESDA.Ā The graphical functionality includes ways to display scatterplots and 3D point clouds, hexagon plots (where each hexagon is shaded in terms of the density of points), boxplots, contour plots, variogram plots and correlograms.Ā In terms of analysis it offers: Variograms, which are effectively a means of displaying the variance between points at various distances or in various directions; Kriging, which is a linear interpolation method for predicting cell values for a regular grid based on a set of observations; methods for assessing spatial autocorrelation and spatial randomness; methods for building spatial regression models; methods for stimating the intensity function of spatial point patterns; and methods for investigating spatial interaction and spatial dependence.Ā S+ArcView integrates the statistics, graphical and GIS functionality of S+SpatialStats and ArcView.Ā Further details of S+ can be found on the Web at:
http://cm.bell-labs.com/cm/ms/departments/sia/S/
Details of S+SpatialStats are on the Web at:
http://www.splus.mathsoft.com/splus/splsprod/spatldes.htm
Geographically Weighted Regression
Geographically Weighted Regression (GWR) is based on multiple regression.Ā Multiple regression is a commonly used statistical technique that involves estimating the relationship between one dependent variable and a set of predictor variables that are assumed to be independent of one another and identically distributed about the mean.Ā Thus an assumption that is inherent when applying multiple regression to spatial data is that there is no spatial variation in these attribute distributions within spatial subsets of these data.Ā These assumptions are fundamentally flawed when applied to geographical data, however there are many examples of the use of this statistical technique in geographical enquiry.Ā The difference between standard multiple regression and GWR is that the later enables parameter estimates which control the importance of specific dependent variables to vary locally according to a defined kernel that weights the importance of observations from a given point by some kind of distance function.Ā he resulting parameter estimates from GWR vary locally and can be mapped in order to examine local variations in the relationship between the dependent variable and its predictor variables.Ā This examination of model deviations or errors is sometimes referred to as econometrics and this specific type is sometimes referred to as the analysis of heteroskedasticity.Ā Basically it involves testing the inequality of variance in the regression errors, which can inform as to where the assumption that the variables used are independent and identically distributed normal variables is most wrong.Ā In other words it can be used examine spatial autocorrelation effects. Monte Carlo simulation provides a means of testing whether the variations in the parameter estimates are due to chance, which is a way of informing about how non-random the fitted model parameters are.Ā Applying this econometric analysis in conjunction with GWR can provide both evidence that the underlying assumptions of the model fitted are wrong and an intricate way of examining spatial autocorrelation effects in spatial data.Ā Mapping parameter estimates or their standard deviations is perhaps the simplest and most easily followed method of providing information about the nature of the autocorrelation.Ā All things considered, the GWR technique can be usefully applied to spatial data and it is well worth considering incorporating it or something similar in SPIN.Ā An important thing to keep in mind though is that the complexities of the econometrics and the intricacies of analysing the statistical models probably make this method inappropriate for use by anyone who does not have a degree in statistics or a good appreciation of the correct use of such methods for spatial analysis.Ā For more information on GWR refer to the following URL:
http://www.geog.ncl.ac.uk/geography/GWR/
Conclusion
The ESDA tools outlined in this report along with the stated expert opinion aimed to provide a useful and representative account of the current state of the art providing a guide to the functionality that we should be aiming to incorporate and develop in SPIN.Ā Not everything was covered in this review explicitly.Ā There are some useful techniques that have not being discussed, such as, spatial interaction models.Ā There are also some useful integrated environments that have not even received a mention.
ESDA involves the concept of spatial patterns or locations of values and their relative magnitude over time.Ā Various aspects of these patterns are measurable and of interest.Ā This includes things like; the extent of the pattern in terms of non-randomness, the extent of the pattern in terms of clustering, the evidence of spatial correlation, and the implied spatial association between variables over various (possibly overlapping) time ranges.Ā Sometimes there is a temporal lag indicative of cause and effect relationships in spatial data values that can be measured.
SPIN should not be aiming to incorporate absolutely everything available that can be useful in an ESDA context.Ā One reason is that a bulky system is hard to maintain, however, the main reason is that this would be very hard to make user friendly.Ā Even experts would find it hard to fathom what tools are best to apply to their data and in what order if the system contained a plethora of tools that essentially did the same thing.Ā In other words: Why have a hundred different tests for clustering when the best few will do?Ā This should not distract from the need to have available example analyses and an extensive tutorial and help system.
SPIN should be capable of: producing summary statistics (mean, median, mode, standard deviation, maximum, minimum, range, etc.); producing exploratory data analysis displays (boxplots, histograms, graphs, etc.); and dynamically linking maps and graphical displays.Ā It should contain standard data mining functionality (NN, GA, rule induction, decision trees) and some multivariate statistical methods (linear and logistic regression).Ā Perhaps most importantly SPIN should contain new types of spatio-temporal data mining tools that can handle the special nature of geographical information.
Multivariate data with both spatial and temporal reference is complex and the challenge is in designing analysis tools able to cope with this complexity.Ā One approach is to create intelligent multidimensional entities that search for interesting patterns and relationships and visualise them as animated colour maps.Ā The search task can be viewed as identifying localised chunks of multidimensional space-time data that contain unusual amounts of unexpected patterns.
In summary, the most important tools to have available are; classification tools that enable data to be evaluated in terms of their membership to an aggregate set, prediction tools which model the data in some way to relate one set of variables to another, and visualisation tools that display the data and can be used interactively as part of the process.Ā There also needs to be a high level of automation, and an extensive help system.
References
- Anselin L (1992) SpaceStat Tutorial.
- Anselin L (1995) SpaceStat Version 1.80 User's Guide. http://www.spacestat.com/
- Brunsdon C (1998) Getting started with LiveMap for XLISP-STAT. http://www.stat.ucla.edu/xlisp-stat/code/incoming/
- Dykes J (1997) cdv: A flexible approach to ESDA home page: http://www.geog.le.ac.uk/jad7/cdv/
- Fotheringham S, Charlton M, Brunsdon C (2000) Geographically Weighted Regression (GWR). http://www.ncl.ac.uk/geography/GWR
- Gahegan M, Takatsuka M, Wheeler M, Hardisty F (2000) GeoVISTA Studio: a geocomputational workbench. Paper presented at Geocomputation 2000.
- Jingsheng M, Haining R, Wise S (1997) Getting started with SAGE.
- Jingsheng M, Haining R, Wise S (1997) SAGE User's Guide. ftp://ftp.shef.ac.uk/pub/uni/academic/D-H/g/sage/sagehtm/sage.htm
- Koperski K, Adhikary J, Han J (1996) Spatial Data Mining: Progress and Challenges. http://db.cs.sfu.ca/GeoMiner/survey/html/survey.html
- Koperski K and Han J (1997) GeoMiner: A knowledge discovery system for spatial databases and geographic information systems. Home page: http://db.cs.sfu.ca/GeoMiner/
- Macgill J (2000) GeoTools home page. http://www.ccg.leeds.ac.uk/geotools/
- Openshaw S (1995) Developing automated and smart spatial pattern exploration tools for geographical information systems applications. The Statistician 44 No.1 p3-16.
- Openshaw S (1998) Geographical data mining: key design issues. http://www.geovista.psu.edu/sites/geocomp99/Gc99/051/gc_051.htm
- Openshaw S, Openshaw C (1997) Artificial Intelligence in Geography. Wiley, UK.
- S+SpatialStats home page: http://www.splus.mathsoft.com/splus/splsprod/spatldes.htm