http://www.geog.leeds.ac.uk/people/a.turner
Centre for Computational Geography
School of Geography
University of Leeds
UK
This paper describes a way to produce a particular type of density information from spatial data for spatial analysis applications or spatial data mining. The specification of an abstraction resolution for a chosen spatial framework is all that is required to produce this density information. This detailed spatial framework used for the production of the density information should also be that used for the subsequent spatial analysis. What is good about this way of producing density information is that once a spatial framework for the spatial analysis has been detailed, no further subjective bias is imposed on the resulting density information (even from NODATA space). In other words, the spatial bias is implicit to the shapes of the frame used to tessellate data space. The focus here is the production of density information for two-dimensional square grids or rasters containing NODATA space that are commonly used in GeoComputation.
This paper describes a way of producing cross-scale density information from spatial data that can be very useful for spatial modelling applications and spatial data mining. Section 3 details how to generate cross-scale density surfaces for two-dimensional (2D) square celled grids. The process involves firstly aggregating data from higher to lower levels of resolution to create a number of density surfaces relating to different spatial scales, then combining these density surfaces to create cross-scale density outputs. Spatial bias in the resulting cross-scale density surface is mainly a consequence of the spatial resolution and spatial extent of the input grid, which are arbitrarily defined. The function used to combine surfaces relating to different spatial scales also has spatial connotations, but for any result the effects are everywhere equal. NODATA areas are handled so they do not bias the result. These include areas beyond the spatial extent of the study region and areas within the spatial extent of the study region for which data is not available.
Fortran programs for generating cross-scale density surfaces from 2D grids are on the Web at http://www.geog.leeds.ac.uk/people/a.turner/programs/. These programs have little in the way of optimisation as yet and require a considerable amount of space and perform a considerable number of calculations for even moderately sized problems. Java versions are currently being written as part of the SPIN!-project with the aim of developing them into exploratory spatial data analysis (ESDA) tools and integrating them into the spatial data mining system that is being built, (details of the SPIN-project are on the Web at http://www.ccg.leeds.ac.uk/projects/spin/).
Section 2 tells a story of how the method of generating cross-scale density surfaces came about. Section 3 concerns data and computational issues. Section 4 details the application of the method for a 2D grid of square cells and outlines an analogy involving a type of kernel. Finally, Section 5 outlines some ideas for developing the method into a spatial data mining tool.
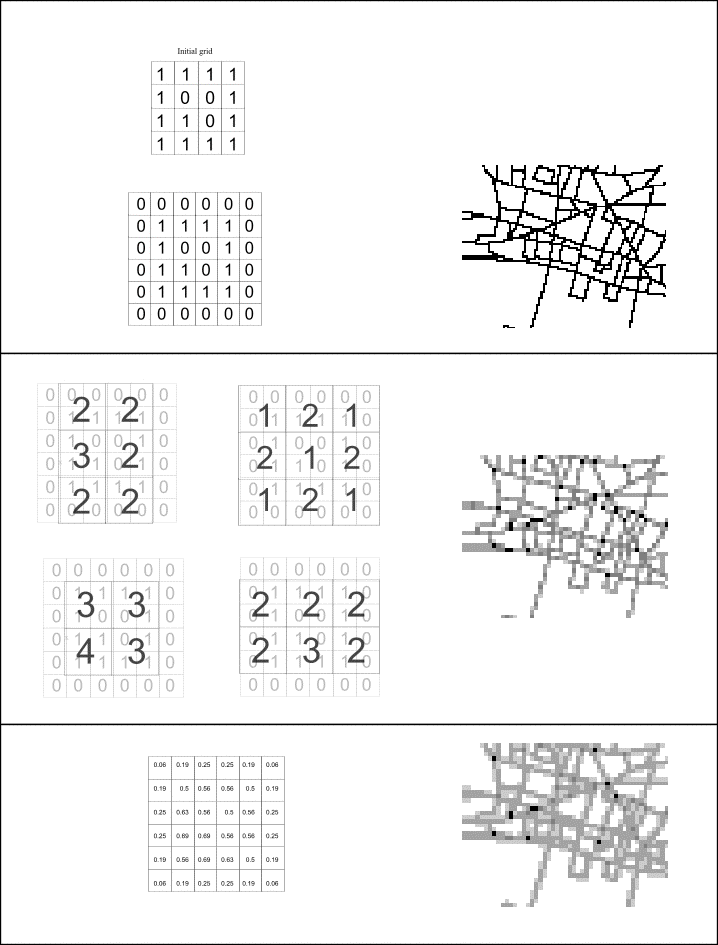
For the modelling exercise reported in Openshaw and Turner (1999) a way of aggregating grids was needed to fit data into a common gridded spatial framework. Aggregating grids may at first seem simple, however a simple approach that uses a single origin for the aggregation is spatially biased. Consider a square grid with four rows and four columns where each cell has a height and width of one and a binary value. Now, there are four ways to aggregate the cells in this grid into grids with a cell height and width of two (where the higher resolution cells nest perfectly in the lower resolution cells). Each individual aggregate grid, which is either a sum or average of the nested cells in the initial grid, on its own is spatially biased, but collectively the biases in all the aggregate grids can be shown to cancel each other out. So, disaggregating the four aggregate grids back to the starting resolution (where each nested disaggregate cell is assigned either an equal proportion of the summed value, or the average value of the larger aggregate cell) gives a set of disaggregate grids with coincident cells in a common spatial framework. The result of averaging these coincident grids is different to the original grid, it is smoother, no longer binary and has a greater spatial extent of values. This grid can be reaggregated again in four ways as before. Any of the reaggregate grids are less spatially biased than the simpler aggregate grids based on the same origin of aggregation. Figure 1 illustrates this aggregate-disaggregate-average-reaggregate procedure with a numerical example. The top picture shows a binary grid constructed from a set of lines where each cell containing a part of the line is coloured black and every other cell is white. The picture in the middle of the figure shows a basic aggregate grid of the binary grid (where the average cell value has been assigned). The picture at the bottom shows the aggregate-disaggregate-average-reaggregate grid for the same aggregation origin as the picture above. It can be seen that the aggregate-disaggregate-average-reaggregate grid is smoother and less spatially biased than the simple aggregate grid of the same origin.
Models generated using grids preprocessed with the aggregate-disaggregate-average-reaggregate technique were significantly better than those made with simple aggregate grids. So, next the newly developed aggregation technique was applied to data already in the chosen modelling framework to see what further advantages there might be.
At first, grids in the modelling framework were disaggregated to a higher level of spatial resolution and aggregated once. Then it was discovered that disaggregating and aggregating grids a number of times could produce richer (yet more useful) data surfaces for modelling with. It was also found that aggregating and reaggregating grids and aggregating beyond the modelling resolution could produce yet more useful data surfaces for modelling with. Various experiments demonstrated the benefits of using density surfaces of a single variable at different scales in the same model. It became clear that dependent variables (those being predicted by the models) were related to the predictor variables across a range of spatial scales. However, it was felt that modelling using many variables was probably not as good as modelling with just a few. So, the next logical step was to develop cross-scale surfaces at a given resolution by combining density grids of a single variable relating to different spatial scales.
To minimise spatial bias in the generated cross-scale grids, what was needed was to consider all possible aggregation origins at each scale. At each scale all the results from different origins needed to be averaged and all the averaged results from each scale needed to be combined to form a surface at the modelling resolution. Subsequently, cross-scale density surfaces that were combinations of averages at all scales from the initial resolution of the input grid to the resolution at which a single cell would cover the entire study area were produced for modelling. Maps of these surfaces looked promising and indeed the modelling results were encouraging, but there was still something not right.
One modelling exercise involved estimating population density and one of the predictor variables we were using was the cross-scale density of the road network. On land near the coast, the cross-scale road density surface was being systematically underestimated. Adding variables to counter this effect in the models was undesirable, and at the time attempts to directly estimate cross-scale population density (rather than simply population density per se were not considered). Anyway what was really needed was to treat the sea differently to the land. What emerged was a general strategy for coping with not applicable or NODATA areas. The strategy involved applying the aggregation procedure on two grids simultaneously; one grid of values as before but with NODATA replaced with zero values, and a binary grid with a value of one if the value grid had a value and zero otherwise. Aggregated grids derived from the binary grid were used to normalise the respective aggregated grids derived from the value grid prior to averaging and combining them all to produce the resulting cross-scale surface. By masking ocean seas and lakes to derive a binary grid representing the land surface, cross-scale surfaces with less of a coastal edge effect were thus produced. Again the models showed a significant improvement justifying development of the preprocessing technique.
The process of creating cross-scale density surfaces described above involved aggregating an initial density surface from an initial resolution (given by the size of a single cell) all the way up to a resolution given by the maximum of the width or height of the initial grid. For now consider geometric aggregation and cross-scale combination of 2D square celled grids where cells at the next scale up have twice the width and height (four times the area) of those at the current scale and all scales are equally weighted. So, as above, there are four aggregated grids of the initial grid because there are effectively four origins at which to start the aggregation to produce different grids at the next level of resolution. There are also four ways of aggregating each of these aggregate grids and indeed four ways of aggregating each of these, thus at the nth stage of aggregation there are 4n aggregate grids. As the number of grids increases geometrically from one resolution to the next, the number of data values stored in each aggregate grid decreases geometrically. This compromise means that approximately the same amount of data is stored and processed for each scale in order to compute the result.
In order to handle effects of aggregate grid cells that cross the original study area boundary, approximately nine times as many data values are stored at each level of resolution in the current implementations. These values can be thought of as a boundary around the data space storing aggregate data that overlaps the edge of the defined study area. To control other NODATA effects related to regions within the current spatial extent, space and computational requirements are doubled on top of this. More space and computation is needed for averaging and combining results together, so all in all, for an n by n grid, space for approximately 50n2 values is needed and approximately 50n2.5 calculations are performed to create a 2D geometric cross-scale density surface.
Various cross-scale surfaces can be constructed by combining aggregate grids at different scales in different ways. The way they are combined has spatial bias implications related to scale, but anyway, it might be desirable to weight some scales more than others in the cross-scale combination. Developing an exploratory spatial data analysis (ESDA) tool based on this idea is discussed in Section 5. To store each density surfaces at each scale requires additional space.
Much geographical data is stored as 2D grids. Some are density surfaces (or some proxy or other relative measure, e.g. counts, distances, and spectral band intensities), and some are not. In the case where grid cells do not have values related to a continuous scale, they must first be preprocessed into binary location grids. This involves re-coding a selection of grid values with a value of one and the rest (with the exception of NODATA values) with a value of zero. In a spatial data mining context it may be desirable to produce cross-scale surfaces for every permutation requiring a considerable amount of space and processing. To apply the method to vector data (points , lines, areas and regions) preprocessing involves rasterising the data. In transforming data from vector to raster there are various things to take into consideration and various options available. In some cases it may be appropriate to make the initial density surface binary and code cells as to whether or not they contain specific points lines areas or regions. In some cases, a more sophisticated initial density measure might be desirable, such as a measure of the number of points, the length of lines, and the area/volume of regions with a particular characteristic. Sometimes it may even be desirable to assign grid values derived from related attributes of the points lines areas and regions. Whichever rasterisation method is used, the resolution of the grid generated has a major effect on the cross-scale density output generated. For binary rasterisations often the most useful looking cross-scale density surfaces are the result of processing an initial grid with an initial resolution such that half the cells have a value of zero and half a value of one. Really though, there is no right global proportion to aim for. Arguably it is best to process the data at as high a resolution as can be done in the time that is available. However, spatial data contains errors and is generalised, which means that a compromise in the chosen initial resolution often needs to be made. An initial resolution that is very high creates the need for a lot of processing, can have undesirable error propagation and might not be sensible given the level of precision and generalisation in the vector data being rasterised.
The evolution of the aggregation-disaagregation-average-reaggregation procedure was described in Section 2 and illustrated in Figure 1. In this section a similar numerical example illustrates how the method works on 2D grids in order to cope with NODATA areas. Prior to this, the process without regard for NODATA is shown to be equivalent to performing a single operation of passing a kernel over the initial grid in a particular way.
So, to achieve the same result as the numerical grid at the bottom of Figure 1 a single grid operation could have been performed using a type of kernel. To create the output for a single cell what was done was effectively the same as: multiplying the coincident input grid cell by four, adding the sum of the adjacent cells (above, to the left, to the right, and below the coincident input grid cell) multiplied by two; adding the sum of the diagonal neighbours (the cells above and to the right, above and to the left, below and to the left, and below and to the right); then dividing the result by sixteen. This process can be thought of as applying the weighting kernel shown in Figure 2 to each cell of the input grid.
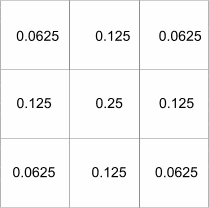
In order to create the aggregate grid at the next level of resolution the kernel can be reapplied but with a dispersion factor so that instead of applying the weights to the immediate neighbours of the previous result, the weights apply to the cells double the distance away. For the next scale up from this again the kernel can be applied to the result from before, doubling the dispersion factor, and so on. Considering the process as repeated applications of a kernel with a dispersion factor is useful because it covers several steps in one go and a version of the program implemented this way was faster. A problem with NODATA was lurking and is picked up again below, but none the less the kernel version of the program offered a welcome optimisation and the new way of looking at the processes had other benefits.
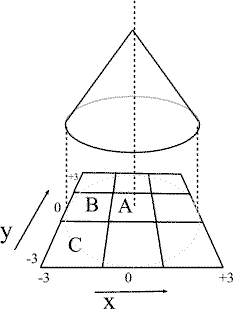
Although the kernel in Figure 2 undoubtedly has symmetry, it can still be argued that it is spatially biased. A less spatially biased kernel can be created based on the area of a circle, or the volume under a cone, or the volume under some other 3D surface where the height of surface is a function of distance from the centre. Consider the conical kernel in Figure 3. Assume that the height h and radius r of the cone equal three (for simplicity), so each cell has a height and width of two. The total volume is given by Equation 1 and the equation of the surface of the cone is given by Equation 2. So, integrating over the correct intervals; the area covering cell A is given by Equation 3, the area covering cell B is given by Equation 4 and the area covering cell C is given by Equation 5. So, A is covered by 31.6% of the volume of the cone, B is covered by 12.9% and C is covered by 4.2%.
Equation 1 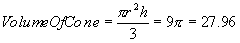
Equation 2 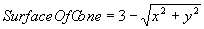
Equation 3 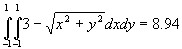
Equation 4 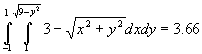
Equation 5 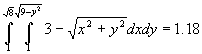
Supposing the shape was a hemisphere instead of a cone with a volume given by Equation 6 and surface equation given by Equation 7, then cell A would be covered by 20.4% of the volume of the cone, B 13.9% and C 6.0%.
Equation 6 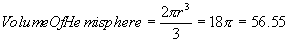
Equation 7 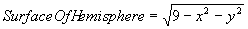
Clearly, using a hemisphere kernel would produce a smoother cross-scale surface than using the conical kernel as the kernel weights are more evenly spread. Experiments to look into the effects of using different kernels on the resulting surfaces are still being performed. For kernels other than that depicted in Figure 2 the cross-scale results are not equivalent to those of a geometric aggregation, but nonetheless they can be thought of as a sort of cross-scale density surface. This idea is revisited in Section 5, but next to the strategy of coping with NODATA that limits somewhat the kernel analogy.
At the top of Figure 4 below is an initial grid as in Figure 1 but with a NODATA value in one of the cells as opposed to a zero. The grid below and to the left of the initial grid in Figure 2 is the value grid where the NODATA cell value has been replaced with a zero. This is done so that the NODATA value is not counted in aggregates of the value grid. Below the value grid are the aggregates grids derived from it, these are the same as those in the middle of Figure 1. On the right side of Figure 4 (below the initial grid) is a binary grid with a value of one where the initial grid has a value and zero otherwise. The grids below this normaliser grid are aggregates derived from it. Imagine now that each aggregate grid on the left of Figure 2 is divided by the respective normaliser grid on the right to give another set of four grids. Imagine that these grids are dissagregated to the initial grid resolution assigning an equal proportion of each normalised value to each cell (a quarter). And finally imagine that all of these coincident normalised cell values are averaged. The result is the grid at the bottom of Figure 4. To get the answer a scale up from this, each of the eight aggregate grids in the middle needs to be aggregated in each of four possible ways as in the first iteration on just two grids (the value grid and binary normaliser grid). At the second iteration, sixteen normalised grids would then be produced by dividing the aggregate grids derived from the value grid with their respective grids derived from the binary normaliser grid. These sixteen grids would again be disaggregated to the initial grid resolution, where again each cell would be assigned an equal proportion (a sixteenth). The coincident grids would then be averaged to produce a surface at the end of iteration two. For large input grids this process would continue several times until the aggregate grid cell size becomes larger than the initial grid. Results at different scales once produced can then be combined to produce various cross-scale density outputs.
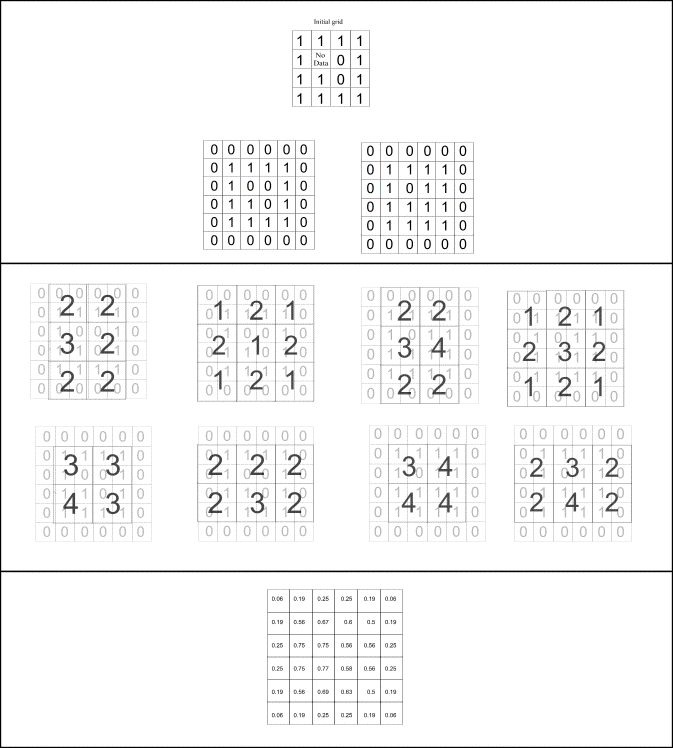
The benefits of the extra work may be hard to appreciate with the numerical example shown above because it is a very small grid. Regardless, comparing the grid at the bottom of Figure 1 with the grid at the bottom of Figure 4 the difference in the answer is apparent and makes logical sense. To avoid inferences being made, either at this stage, or after the cross-scale combination has been done a post-processing step is needed to mask the original NODATA areas. In order to clarify matters, the reasoning behind the process is now explained again.
Regard each initial value grid as a count and consider density as count divided by area. Now, consider an aggregate cell at the first iteration that contains a NODATA cell at the initial resolution. The aggregate count of values is no different than if the NODATA cell had initially contained a zero, but the respective normaliser grid records the total area of data space to which the aggregated value applies. Dividing the value in each aggregate grid cell by the respective normaliser grid cell therefore gives an estimate of density. This is effectively the same as assigning an average density value to the NODATA cell in the first place, but whichever way it is regarded, the resulting density surface is not biased by the distribution of NODATA areas. In the iterative process, it is not the average grid that is reaggregated but the aggregated count and normaliser grids, and the normalising and averaging at each scale is always done as the last step. It is important to appreciate that this is different to taking the resulting average density at each scale and aggregating it. However taking the resulting average density and aggregating it does produce an interestingly similar surface.
A consequence of the intricacies of normalising and averaging when there are NODATA values is that it is no longer easy to get the same answer by applying kernels as before. Applying the kernel shown in Figure 2 to both the value grid and normaliser grids and dividing the former by the later gets an answer, as in Equation 8, which is interesting but not the same, not really a density. The difference is the difference between Equations 8 and 9, where va,b is the value grid cell in row a column b, na,b is the normaliser grid cell value for the same cell and d is a measure of dispersion, which for the first iteration equals one.
Equation 8 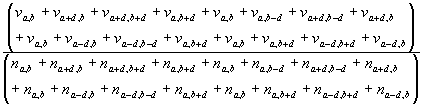
Equation 9 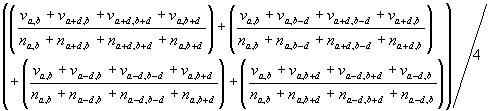
The above equations are written for ease of comparison and not in their most compact form. Clearly if all the n values equal one then Equation 8 yields the same answer as Equation 9. If all n values equal zero then all v values will also be zero as all the cells in the grid pertaining to will originally have been coded as NODATA. In Equation 9 if any of the denominators are equal to zero then so would be the numerator. In this case the result of the division should be defaulted to zero for the sum prior to the division by four.
Below an algorithm for creating geometrically aggregate cross-scale density surfaces for 2D square grids is presented by way of summary:
Step 1
Put a NODATA boundary around the input grid
with a thickness equal to the maximum of the width and height.
Step 2
Duplicate the bounded grid and replace the
value of NODATA cells with zero (create an initial value grid).
Step 3
Duplicate the bounded grid and replace the
value of NODATA cells with zero and code all other cells with a value of
one (create an initial normaliser grid).
Step 4
Aggregate the grids from Steps 2 and 3 into
grids with cells of twice the width and height (nesting four cells at the
initial resolution) in each of the four possible ways.
Step 5
Divide the aggregate value grids by their respective
aggregate normaliser grids.
Step 6
Average the results from Step 5 at the initial
level of resolution and keep the result
Step 7
Repeat Steps 4 to 6 (but using the previous
aggregates from Step 4 not the grids from Steps 2 and 3) until the cell
size of the aggregate grids is greater than the size of the input grid.
Step 8
Combine all the results from Step 6 using a
weighted sum.
This section describes some variations and extensions of the method and describes how it might develop into a spatial data mining tool as part of the SPIN!-project.
First, try to envisage how the method would work in 3D by thinking of operations on cells as blocks rather than as flat 2D objects. For the various types of 3D data there are, creating cross-scale density surfaces can be done in various ways. Often all three dimensions or axes x y and z will want to be treated the same, such that a distance in every direction is treated the same. However, for much of the 3D data of concern to geographers, gravity pulls mass in one direction not orthogonal to the z-axis (but orthogonal to the other two axes x and y). Because of this fundamental difference, distance on this z-axis may want to be treated differently and possibly even asymmetrically. As with everything, what is most appropriate will depend on what data are available and what process is ultimately going to be modelled. If it is deemed appropriate to treat space the same in all directions thinking of a 3D version of the cross-scale density algorithm is not too difficult. The same data issues are relevant but the problems are an order of magnitude greater. The boundary at Step 1 of the algorithm (presented in Section 4 above) increases the size of a cube input grid by a factor of 27 not nine. There are eight different aggregation origins at each level of resolution at Step 3 not just four. Other than that, everything else would work pretty much the same. A 3D implementation of the method can be applied in many fields including; environmental modelling, seismic research, geology, molecular biology and astrophysics. The general applicability of the method endows it with massive potential.
For some types of modelling it may not be necessary to factor some scales. Indeed the weighting function used to combine data across a range of scales needs some serious consideration. To focus in on a particular scale it is sensible to weight scales further away less that those close by. In the geometric aggregation described, clearly not all scales are considered, there are many between as well as those beyond. It may be that the most useful combination of scales does not follow from a geometric aggregation. This requires many more experiments to investigate. For my PhD I am analysing road traffic accident (RTA) patterns. Modelling the spatio-temporal distribution of RTA provides an opportunity to do some of these experiments. In order to predict RTA rates for any area there are many different things to take into consideration. Leaving most of these issues a side imagine trying to predict the number of accidents for an area based on the road density alone. The road density surface shown at the end of the presentation given at Geocomputation2000 is a 2D cross-scale density surface of roads stored as vectors in Ordinance Survey data made available via DigiMap (http://edina.ed.ac.uk/digimap/) under the CHEST agreement. To produce the surface a chunk of vectors were clipped and rasterised at 100 meter resolution into a 9000 by 9000 meter grid (90 rows and columns) where each cell was assigned a value related to the length of road it contained. Aggregating this grid using the cross-scale density algorithm generated density surfaces at 100 200 400 800 1600 and 3200 scales and for each, the middle 30 rows and columns were kept. Moving along 3000 meters from the first origin of rasterisation, the next overlapping 9000 metre by 9000 metre chunk was rasterised, processed and the middle bit kept as before. This process was continued until the results covered the whole of Great Britain then results from each scale were joined together and then combined. It is worth noting that this process is inherently parallel because different chunks can be processed at the same time. The results of computing each chunk do not depend on each other and the process is computationally intensive so lends itself to distributed computer architectures.
So, the method can be easily parallelised and can form the basis of a spatial data mining tool. For the spatial data mining system being built in the SPIN!-project such a tool should be highly automated and probably also temporarily keep outputs for each scale computed so that users can control the cross-scale combination.
Openshaw, S. (1999) Geographical data mining: key design issues. (http://www.geovista.psu.edu/sites/geocomp99/Gc99/051/gc_051.htm)
Openshaw, S. and Turner, A. (1999) Forecasting global climatic change impacts on Mediterranean agricultural land use in the 21st Century. (http://www.geog.leeds.ac.uk/people/a.turner/publications/OpenshawTurner1999.html)
The SPIN!-project Web site http://www.ccg.leeds.ac.uk/projects/spin/
This work has been supported by EC grants ENVA4-CT95-0121 and IST-1999-10536.