Predicting the impact of global climatic change on land
use patterns in Europe
Centre
for Computational Geography
School of Geography
University of Leeds
UK
This paper was presented by Stan as a key note speech at the International
Conference on Modelling Geographical and Environmental Systems with Geographical
Information Systems in Hong Kong, 1998.
Summary
The paper describes the development of a prototype Synoptic Prediction
System designed to estimate possible impacts of global climatic change
on land use patterns across the European Union (EU). Designing such
a system is a challenging task because many of the theoretically desirable
data sets are either not available or do not exist whilst significant uncertainties
are apparent in the available data. Additionally, process knowledge
is woefully deficient as virtually all the principal mechanisms for linking
the dynamics of the physical environment and climate with the associated
socio-economic systems are poorly understood. Our belief is that
currently no computer models exist which can appropriately address this
task and that presently a synoptic GIS style of approach is probably the
best way of making broad brush geographical predictions of the possible
impacts of global climatic change on land use for around 50 years hence.
So, the paper describes the construction and application of a prototype
Synoptic Prediction System that employs a mix of GIS, neurocomputing, and
fuzzy logic technologies to attempt this almost impossible but potentially
extremely important task.
Keywords: GIS, neurocomputing, fuzzy logic, climatic change, land
use forecasts
Contents
1. Background and Context
2. Design
of a Synoptic Prediction System (SPS)
2.1 Basic design objectives
2.2 Basic System
2.3 Problems
2.4 Stages in Operationalising a SPS
3.
Assembling, aggregating, and estimating the data
3.1
The spatial interpolation problem
3.2
Creating a common spatial database
3.3 Estimating the Population distribution
3.4 Climatic Data
3.5 Other
Environmental Data Sets
4 Results of
Modelling Land-use change.
4.1 Now Land-use
Modelling
4.2 Future
Land-use Modelling
4.3
Assessing the impact of change
5. Conclusions
1. Background and Context
This paper is based on ongoing research undertaken by the authors on a
European Commission funded project, MEDALUS III, concerned with Mediterranean Desertification and Land Use.
MEDALUS III consists of a
wide range of topics aiming to analyse and model various aspects of environmental,
climatic, and land use change at different spatial scales in the Mediterranean,
see McMahon (1998). Our overall objective as part of this project
is to add a socio-economic dimension to the physical models of land degradation.
This task can be tackled in various ways. The strategy described
here involves developing a modelling methodology able to link estimates
of socio-economic data with available physical-climatic data in order to
express forecasts of climatic, environmental, and socio-economic change
in terms of agricultural land use impacts. By the end of the project
we hope to have packaged up the various modelling components into a Spatial
Decision Support System aimed at politicians, land use planners and the
public to raise awareness of the possible impacts of land degradation and
devise mitigation strategies to alleviate the problem.
There is a growing likelihood that global climatic change will soon
start to have a visible and increasingly fundamental environmental and
socio-economic impact within the next 25 to 50 years across many parts
of the world. In some regions the effects may well be unnoticed or
are irrelevant or are well within the capacity of existing ecosystems to
cope; however, in other regions the environment is far more fragile and
susceptible to serious problems. In these regions it is possible
that even small changes in the climate may be sufficient to cause a major
impact on the environment and socio-economic systems that relate to it.
The research challenge is to identify a plausible way of making reasonable
predictions of climatic change impacts on land-use for 25 to 50 years hence
as a possible basis for raising awareness and creating a framework for
action. The hardness of this challenge should not be underestimated,
but equally there is an increasing urgency to know something of what may
be happening to our world in the medium term future so that thinking and
strategic planning may be proactive rather than purely reactive.
From a methodological perspective there has been very little research
performed on predicting future land use patterns on a local let alone national
or European scale. Most computer models that exist are generally concerned
with only very limited aspects of the problem; for instance, regional employment
change or population dynamics. An exception is the work by the CLUE
Group (see de Koning et al (1997), Veldkamp and Fresco (1996, 1997),
Verburg et al (1997)). The CLUE modelling framework (The Conversion
of Land Use and its Effects) is based on a multi-scale stepwise regression
approach that attempts to analyse and model land-use and land-use change
as a function of socio-economic and biophysical factors at an aggregate
spatial scale for China, Ecuador, and Costa Rica. The model is a
linear continuous time simulation at a fairly coarse spatial scale; ranging
from 7.5 km2 for Coasta Rica to 32 km2 for China.
For the European Union (EU) we feel that something far more sophisticated
is needed. The basic requirements are that; the level of spatial
resolution is sufficiently detailed to be useful, the key driving factors
and process mechanisms that link human and physical environments are explicitly
incorporated, and that the model is driven by climatic and environmental
change. Additionally, the model should seek to make good use of the
research and model results produced by other teams involved in the MEDALUS III.
The principal justification for a modelling approach is that a more
traditional mapping of indicators will probably fail to incorporate many
of the most important process variables, such maps are static, they can
only realistically be produced for small case study regions (inhibiting
the formation of an objective global overview), and the data and methodology
would be hard to standardise so that like may not be compared with like.
This is not a criticism that mapping land degradation and of environmentally
sensitive areas for this or that part of the EU is not useful, only that
this may be the wrong approach if the objective is to provide a synoptic
overview of global climate change impacts on land degradation across the
whole Mediterranean climate region of the EU.
Additionally, if scientific research on land degradation processes is
to have a major political and public impact commensurate with the academic
and theoretical importance of the subject then a means needs to be found,
however imperfect, to translate the scientific research into a form that
non-technically sophisticated decision-makers and a non-technically sophisticated
public can understand and appreciate. GIS provides a good map based
communications medium but also what are needed are consistent results that
are mapable, based on the best science at the present moment in time, and
which show what global climate change impacts are on agricultural land-use.
Section 2
outlines the structure of a Synoptic Prediction System (SPS) which is designed
to meet this challenge. Section 3 describes how the various data components were assembled. Section 4 discusses the operation of the system to make both nowcasts and forecasts
of future land-use patterns. Section 5
presents some more general conclusions.
2. Design
of a Synoptic Prediction System (SPS)
2.1 Basic design objectives
The challenge is to devise GIS based computer modelling systems that are
able to link changes in climatic, physical environment, and socio-economics
to agricultural land-use in a land degradation context focusing on the
effects of global climate change. The objective is to model the relationship
between climate (temperature and rainfall), soil characteristics (permeability,
texture, fertility, parent material), biomass, elevation, population densities,
and other socio-economic variables to predict contemporary land-use, then
forecast future land-use patterns under various different climatic change
scenarios. What is needed, in our view, is some kind of Synoptic
Prediction System (SPS) which is intended to function rather like a long
term weather forecast. Regrettably and unavoidably the geographical
details will be error prone and maybe even "wrong" but the expectation
is that the more general synoptic or broad brush forecasts will be reasonable
once they have been aggregated and generalised to a sufficiently coarse
level of meta scale detail. The term "synoptic" derives from the
desire to include a broad range of relevant general indicator variables
whose interrelationships can be modelled to justify the synoptic designation.
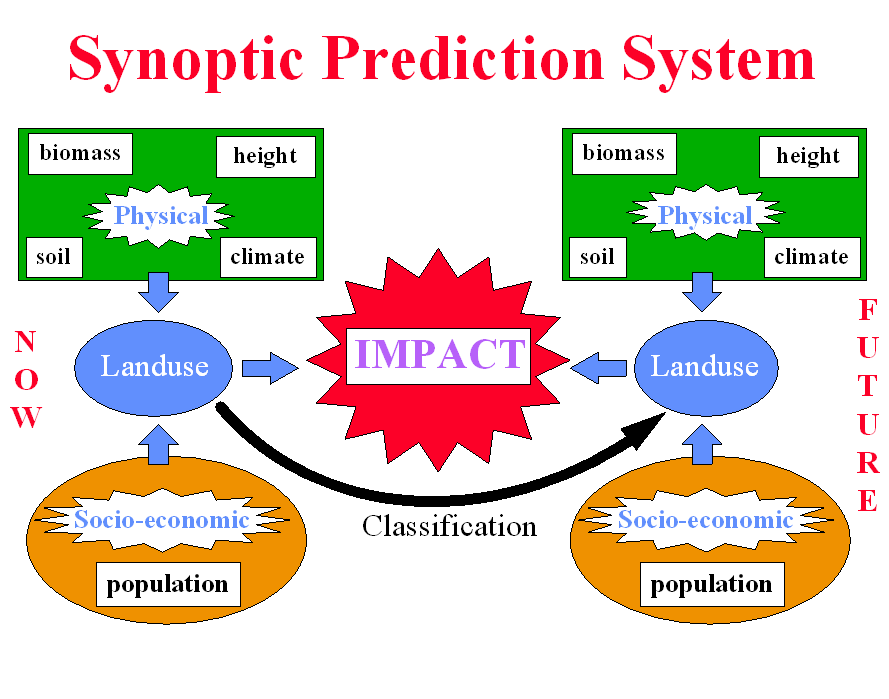
2.2 Basic System
The basic system is outlined in Figure
1. The simplest view is that of a series of key input variables
that are related via a computer model to some outputs. It can be
considered to be some kind of complex regression model except that the
mapping of the inputs on to the outputs employs a neurocomputing approach
as the non-linear relationships are little understood and too ill defined
for more conventional statistical or mathematical modelling specifications
to work well. A fuzzy inference style of approach would probably
work better, but initially it is easier to use artificial neural networks
- especially as training data are not in short supply. Table
1 briefly outlines some of the strengths and weaknesses of models based
on artificial neural networks; see also Openshaw and Openshaw (1997).
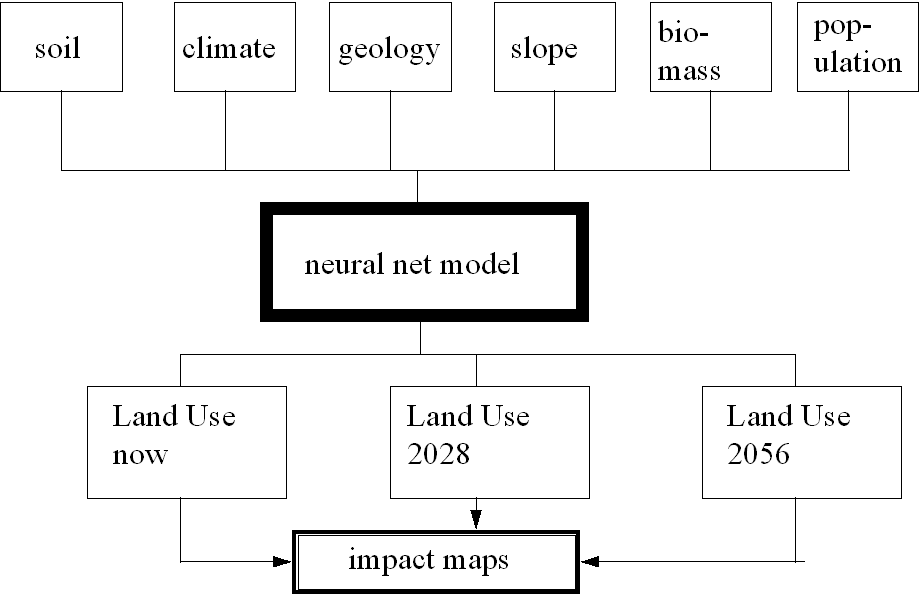
In operationalising Figure
1 the choice of input variables is restricted to those available for
MEDALUS III research which
reflect "obvious" processes. Figure
2 outlines the SPS in greater detail. The available variables
are not ideal, but then probably no one knows what would be ideal in this
context. Nevertheless Figure
2 shows that we are using the most obvious variables. Table
2 gives the full list of 18 predictors used in the modelling which
is described in Section
3.
2.3 Problems
There are various problems associated with the modelling structure displayed
in Figure
1 and Figure
2. The principal one is that the relationship between climate
and environment and land use is not conditioned by the laws of physics
or chemistry or biology but involves many ill defined human factors.
In particular, the relationship between the input physical variables and
land use is mediated and affected by at least the following: available
technology, market mechanisms, historical tradition, inertia, culture,
and various economic factors such as subsidies. All these aspects
are currently invisible to the model and are not directly present in any
of the available data; however their integrated effects are present in
current patterns of land-use that the neural net model is being asked to
represent. It would of course be nice to have a model into which
the price of crops, EU agricultural subsidies, irrigation practices, and
farmer behaviour could be input and then operationalise this model at a
fine spatial scale for the entire EU. However, such a model is probably
beyond technological feasibility and current data availability, although
doubtlessly such models could be built one day by discovering how to model
individual people in artificial world laboratories; a bottom-up approach.
However, this dream is probably 10 or more years off in the future and
to perform the research now we are forced by scientific circumstances,
data restrictions and ignorance to adopt an aggregate top down approach.
It is hoped that the missing variables are invisibly present in the data
that are used and are thus taken into account, somehow, by the neural nets
that are applied. This is probably a most optimistic view particularly
when the forecasts made for 2048 assume a continuation, at the same level
as today of these invisible influences; if indeed they have any direct
impact at all. Unfortunately, we have no choice in this matter given
the urgency of the task and the necessity to do the best we can with current
technology, knowledge, and data. However, in defence we would note
that there is not a necessary nor a direct relationship between overall
model performance and the accuracy of the individual model subcomponents
or different data layers. Indeed one of the most compelling justifications
for a fuzzy approach is the belief that there can come a point in conventional
models where improved precision and more detail in systems of equations
can result in a deterioration of performance; see Kosko (1994).
A further word of caution. The results will critically depend
on the quality of the inputs, and although this has not yet been quantified,
we believe the current SPS uses the best available data even though it
is deficient. The aim is to provide broad brush forecasts which
are not necessarily accurate but which offer a synoptic view of the likely
impacts. The SPS simultaneously demonstrates what is needed to model
the process of land degradation as well as indicating the likely effects
of global climate change on land use. If the results are what is
required then doubtlessly their accuracy can be improved. If critics
do not like this approach, then let them demonstrate that they can do better
given the same objectives, the same data restrictions and research resource
constraints that apply here. What is proposed here captures the very
essence of a GIS based approach to modelling environmental systems from
a geographical perspective.
2.4 Stages in Operationalising
a SPS
The system outlined in Figure
2 involves the following steps:
Step 1: Assemble the data for a common EU wide geography
for the present day (circa 1991).
Step 2: Obtain forecasts for these variables for 25 years hence
(notionally 2023) and 50 years hence (designated 2048) for the same geography.
Step 3: Construct neural nets to model the relationship between
climate (temperature and rainfall), soil characteristics (permeability,
texture, fertility, parent material), biomass, elevation, population densities,
and other socio-economic variables to predict contemporary land-use patterns.
Step 4: Compute estimates of land-use for 2023 and 2048 by using
forecast values of the inputs to the neural nets and also investigate different
climatic change scenarios.
Step 5: Create maps of the impact by comparing these forecasts
with predictions for the present day.
Step 6: Consider modifying the forecasts and the predictions
to reflect knowledge expressed as fuzzy rules and repeat Step 5.
Section 3 describes Steps 1 and 2. Section
4 covers 3, 4 and 5 whilst step 6 is yet to be completed.
3.
Assembling, aggregating, and estimating the data
3.1 The spatial
interpolation problem
One major reason that much of the environmental change research has ignored
the socio-economics is the lack of socio-economic data with an appropriate
level of spatial and temporal detail so that they can be directly linked
to the outputs from the environmental models; see Clarke and Rhind (1991).
Quite simply major differences in quality, scale, and aggregation between
existing physical environmental-climatic data and socio-economic data present
serious obstacles to the straightforward integration of the models.
Physical models of land degradation generally operate at more detailed
spatial and temporal scales compared to existing socio-economic models.
Socio-economic data generally relates to irregularly shaped zones that
are historically unstable and subject to continuous change, whereas physical
environmental-climatic models tend to use and produce data in regular gridded
structures albeit at a range of different scales.
Using GIS most available environmental data for the EU can probably
be manipulated into a regular grid orientated at a spatial resolution of
approximately 1 km2. A grid was selected as the framework
in which to store, manipulate, link and map the data since it offers the
greatest flexibility in aggregating upwards and can yet still provide a
realistic representation of regional or local variation provided the grid
cells are sufficiently small. A geographical latitude-longitude projection
was chosen as a compromise given the traditional problems in map projections
regarding the representation of distance, direction and area distortion
of the data caused by the curvature of the earth. A 1-decimal-minute
(1 DM) resolution (which is roughly equivalent to a 1 km2 for
most of the EU) was selected as providing the most appropriate and probably
the best possible level of spatial resolution that was practicable for
this research.
A common spatial framework for all the available climatic, environmental,
and socio-economic data is an essential pre-requisite before any modelling
can be attempted. This is not a trivial task as typically the climatic
data are produced at a coarser scale than the socio-economic which is itself
far coarser than that at which many physical models have been applied.
Aggregation upwards is fairly trivial but interpolation from coarse to
finer levels of spatial resolution is far more problematic and error prone
yet this is an unavoidably essential activity that needs to be mastered
before much progress can be made. Virtually every data source involved
in the SPS and described in Figure
2 (see also Tables
2 and 3)
had a unique set of problems associated with it and necessitated various
GIS operations and sometimes modelling applications to create a common
scale data base.
3.2 Creating a
common spatial database
The task of creating a common spatial database for the EU for a 1 DM set
of cells for those variables described in Tables
2 and 3
was not straightforward and involved the following somewhat convoluted
procedures. Initially, attention was concentrated on processing those
variables need to create the population data; see Table
2; using the procedure described later in Section
3.3.
The first data set to be processed was the Global Land 1 km Base Elevation
source data (GLOBE). This provides a grid of 0.5 DM resolution cells
in a geographical projection based on the World Geodetic System 84 datum.
It was imported into ArcInfo. The grid was aggregated to a resolution
of 1 DM where each 1 DM cell was assigned the mean value of the four 0.5
DM cells from which it was composed. Since the average height above
sea level values of this height variable are normalised by the neural net
program the sum or some other composite combination of these values could
have been used. There are several reason for selecting to use the
mean; compared with the mode and median, it is easier to compute since
there are four values being summarised, the loss of data precision is less
than if just a random selection of one of the four values was assigned,
and finally the resulting 1 DM values are still standard distance units
of height above sea level whereas they would not be if the sum had been
used. The grid was clipped to a size of 2205 rows and 2568 columns
which covered the whole of the EU and most of the rest of Europe.
The GLOBE data itself did not need to be projected, but all the other source
data based on different projections had to be transformed. There
are various ways of doing this, they all suffer from problems and there
is a trade off depending on the nature of both the non-nesting aggregations
between the projections and the nature of the spatial variable (whether
it is density, distance or direction related).
Gridded night-time lights source data was imported into ArcInfo, converted
into a polygon coverage and projected from its original Goode Homosline
projection into the required geographical projection using the projection
capabilities of the software. The projected polygons were intersected
with a polygon coverage which coincides with the grid in the chosen 1 DM
spatial framework. A value was calculated and attached to each small
intersected polygon by dividing the night-time lights intensity value by
the area of this small polygon. The intersected polygon values within
each 1 DM grid polygon were then summed and the resulting coverage was
converted into a grid.
Similarly, the Surpop 0.2 km source data was imported into ArcInfo,
converted into a polygon coverage, projection, then intersected with a
polygon coverage which coincides with the 1 DM chosen spatial framework,
and again the intersected polygons were assigned proportions of the population
depending on the area of the intersections. As before the intersected
polygon values within each 1 DM grid polygon were summed and the resulting
coverage was converted into a grid. The total population in the source
data was compared with the total population in the transformed data to
ensure that they were not significantly different. The values in
the transformed data were generally not integer values, although this was
not a problem for the neural net, and an integerised version was created
for mapping purposes.
The Bartholomew digital map data was manipulated into various grids
in the 1 DM spatial framework reflecting either; the location of, distance
from, or density of geographical features. To begin all the various
map layers were imported into ArcInfo and mapped using ArcView. Geographical
features which appeared to be consistently defined across the EU and whose
location, proximity or density were believed to be correlated with population
density were manipulated into location, cost-distance and density layers
respectively. Cell values in location layers were either 0 or 1 depending
on whether the cell lay mainly inside or outside the location of a selected
geographical feature. For the distance layers the spatial analyst
module of ArcView was used to assign the proximity of each cell to selected
geographical features. Creating the density layers employed a point-in-polygon
routine and the grid module in ArcInfo. The density of a selected
spatial variable or geographical feature was calculate at various spatial
scales and some results from certain resolutions were aggregated to coarser
spatial scales where their values appeared to spatially correlate with
population density. The coarser resolution grids were then disaggregated
in a simple fashion where each 1 DM cell was assigned the value of the
larger cell in which it was contained. Using a weighted linear function
all the density grids relating to a particular theme were combined at the
1DM resolution, these combined grids were again mapped to examine the correlation
with population density.
Finally population related variables were included even though they
occur at coarser levels of geography; for instance, population densities
at NUTS 3 scale and RIVM's estimates at 10 km2 scale data.
The values of the 1DM cells were simply assigned the closest value of these
coarser data units. The purpose was to provide a multi-scale contextual
element.
3.3 Estimating
the Population distribution
The principal problem here is that socio-economic data are only readily
available for the EU at NUTS 3 level (equivalent to UK county scale) whereas
the required resolution is far smaller. In the UK there are 64 counties
(all with some pop but there are about 150,000 1 DM cells of which approximately
75,000 are inhabited) and it is these data that are required for the whole
of the EU. This is a massive spatial interpolation problem.
Goodchild et al (1993) reviews a range of spatial interpolation
methods which are relevant to creating surfaces of socio-economic data.
All the methods reported therein suffer drawbacks many of which may only
be overcome by using a "smarter" approach. Deichmann (1996) describes
an intelligent spatial interpolation procedure which makes estimates based
on potential surface accessibility relationships with population related
spatial variables. This basic idea of using surrogate information
to make a smart guess at the distribution of population (and for that matter
any other socio-economic data). This approach is developed further
here by broadening the range of input variables to reduce subjectivity,
then using a neural net to model the non-linear relationship between the
surrogate variables and population density. The neural net is trained
on known UK data and than applied to the rest of the EU.
The aim, therefore, is to use widely available digital map derived summary
variables that are probably related in some non-linear surrogate fashion
with population density; for instance, road network density, distance to
the nearest train station, the location and size of settlements, height
above sea level, etc. The full list is given in Table
2. There is also some external knowledge that can be imposed
on the results; in particular, areas known to be uninhabited (e.g. sea
or lakes) can be set to zero whilst known population counts in NUTS 3 regions
can be used to constrain the predicted values.
The basic idea, therefore, was to use the 1991 Surpop census population
surface to build a neural net based spatial interpolator to relate population
density to a selected set of predictor variables. For each 1 DM cell
the values of the variable chosen to model the population densities were
concatenated into a large file of vectors from which a randomly selected
small training data set of 10,000 1 DM cells was created, together with
the associated Surpop counts. The small number of training cases
reflected a desire not to produce nets that only worked well in the UK.
Ideally, the training data should have been based on data for multiple
countries in the southern EU but no small area census data were available
to us from which Surpop-like estimates might be provided. As a result
there is a risk that population digital map surrogate relationships are
different in the southern EU (i.e. different lifestyle) but there was little
that could be done to reduce this source of uncertainty due to an absence
of data. The EU really does need to organise its basic data resources
to a far better degree than is current. It is really most unsatisfactory
that even NUTS 5 (equivalent to UK ward level) resolution data are not
available throughout the EU and that data copyright and ownership prevents
access to high resolution data even for those applications where the results
are of potential public benefit.
A variety of simple feed forward perceptron networks were applied.
Tests indicated that those nets with a single hidden layer of 25, 50, 75,
or 100 neurons were out performed by a net with two hidden layers each
with 20 neurons in them. The neural net training used a hybrid approach:
first an evolutionary optimiser was used to find a good solution and then
this was fine tuned using a conjugate non-linear optimisation method.
The trained network weights were then applied for the rest of the data
across the EU. The NUTS 3 population totals from Eurostat were used
to constrain the predictions of the 1 DM cells in each area. Errors were
analysed using the Surpop data in the UK at the 1 DM scale but also at
the NUTS 5 scale in Britain and Italy (the only two countries for which
we had these data). Tests were also made of the likely improvement if NUTS
5 data had been available across the EU.
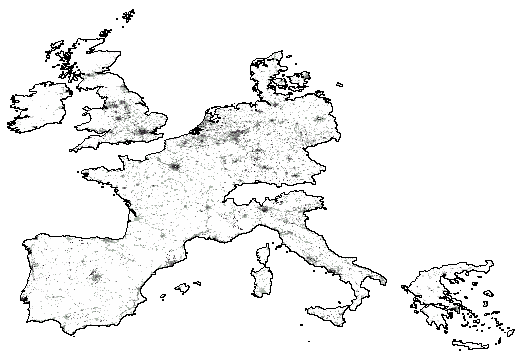
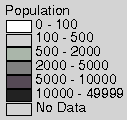
The results appear to be remarkably good; see Figure
3. The predicted surfaces correctly pick up the main features
of the population distribution of the EU even if there is a slight loss
of peakiness. It was surprising how well these surfaces matched reality
given the nature of the input data and with further post-processing to
add lumpiness could further improve the estimates. Use of accounting
constraints based on NUTS 5 data appeared to make little difference to
the results. Finally, forecasts for 2023 and 2048 were produced by
using available EU forecasts for 2023 in NUTS 3 areas, and our own for
2048 (as no official ones existed) to constrain the estimates.
3.4 Climatic Data
This was supplied by the MEDALUS
III team from the Climatology Research
Unit (CRU) at the University of East Anglia. The data was produced
by interpolating measurements from a network of about 50 weather stations
across the Northern Mediterranean to produce 0.5 DM resolution seasonal
average temperature and precipitation totals, see Palutikof and Agnew (1997)
for an explanation of the statistical down scaling procedure. This
data was imported into ArcInfo and the nested cells were simply aggregated
to produce the desired 1 DM resolution data. For temperature data
the mean of the smaller grid values were used and for the precipitation
data the sum of the smaller grid values were used. Based on global
climate change models forecasts of future seasonal average temperature
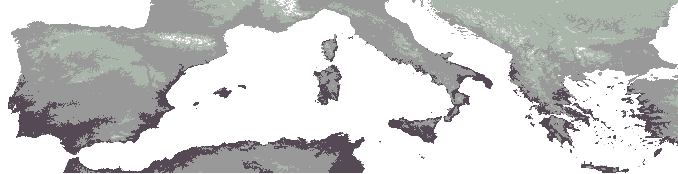
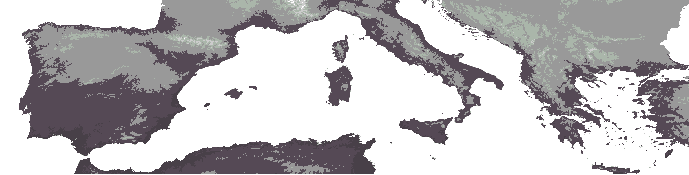
and precipitation totals were also produced by the CRU,
maps of temperature and precipitation for both now and around 2048.
The levels of spatial uncertainty in these data are matched by equal or
greater amounts of climatic scenario forecast uncertainty. Figure
4 and Figure 5 show these
climatic change estimates for temperature and precipitation.
3.5 Other Environmental
Data Sets
Six different classes of soil were selected with the help of a soil expert
based on general similarities between a classification of 26 types provided
in the soil source data. These data are locations on a grid whose
value was 1 if the land belong to the soil class and 0 if it didn't.
A measure of soil quality was also developed to make use of the data on
the characteristics of soils in the source data. The fundamental
physical properties of soil profiles including; the rooting depth, soil
texture, water regime, slope, and existence of impermeable layers were
combined by coding the expert knowledge of the soil scientist into a set
of fuzzy rules and employing MATLAB (a mathematical software package with
fuzzy inference capabilities). The soil quality layer was developed
in this way to make use of the data on the characteristics of soils in
the soil database without having to add each as a separate input into the
Synoptic Prediction System (SPS). It was designed in a similar way
to a general land capability classification, but in the end it is simpler
as it does not take into account all the physical interactions between
the soil and climate.
Estimates of potential biomass were provided by MEDALUS
III colleagues researching at the University of Leeds. This is
the output of a model which translates temperature and rainfall data into
measurements of expected or potential Biomass. The present potential
biomass model is fairly primitive as it does not take into account factors
like the height above sea level or soil type and the output used thus far
is at a relatively coarse level of resolution as it has been built from
30 DM resolution monthly temperature and rainfall data. Nevertheless,
the 30 DM resolution potential biomass data was imported into ArcInfo and
interpolated into the desired 1 DM resolution using the interpolation capability
provided in the spatial analyst extension of ArcView. It is used
here mainly to provide a contextual variable.
The other inputs concern a set of broad land-use categories. There
were two land use source variables attached with the soils source data
which relate to dominant and secondary land use classes. These classes
are derived from a satellite imagery, there is considerable uncertainty
regarding the class of secondary land use but the dominant land use classification
is believed to be relatively accurate. The dominant land use variable
was thus selected as the target land use for which the neural network trained
to classify. Prior to this dominant land-use was aggregated into
four broad categories; arable, trees and orchards, wasteland and others
and each in turn was used as a dependent target variable to train the contemporary
land use classifier. Each cell was assigned a value 0 or 1 depending
on whether it belonged or not to the dominant land use class which was
being modelled. The classification could be greatly improved by assigning
values for each cell, based on the original satellite data, which give
the probability of each cell belonging to a particular land use class;
see Moody et al (1996) and Carpenter et al (1997).
4 Results of Modelling
Land-use change.
4.1 Now Land-use Modelling
The first task was to build another neural network to recognise agricultural
land use based on patterns between: soil type; soil quality; potential
biomass; average air temperature in spring, summer, autumn and winter;
average monthly precipitation in spring, summer, autumn and winter; height
above sea level; and population. The full list of 18 predictors are
shown in Table
3. Three independent neural nets were trained to classify; arable-land
(assumed to be the highest quality), wasteland (the lowest quality land),
and trees and orchards. All these nets had one hidden layer with
50 neurons in it. These classifications were then combined to create
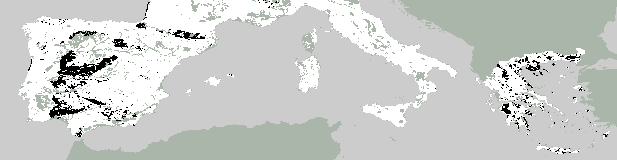
maps of predicted agricultural land-use. The fit is remarkably good;
see for example, Figure
6 showing predicted arable land distributions and the observed.
4.2 Future Land-use Modelling
Predicting the future land use classification involves applying the trained
contemporary neural networks using forecasts of the variables used in the
now land-use classification. For some variables forecasts were unavailable
and for others there was assumed to be no change. The difference
between the two classifications can be mapped to visualise the effects
of global climatic change on land use. Figure
6, Figure
7, and Figure
8 show these predictions for dominant arable, trees, and waste land
use categories. Currently, we would prefer not to interpret these
maps until further computer simulations have been produced. There
is also nothing to compare these maps with right now.
4.3 Assessing the impact
of change
The broad brush maps of predicted land degradation are believable and understandable
so can be used as decision making aids for allocating funds to combat land
degradation. The maps are essentially decision making tools and the
SPS a specific kind of Spatial Decision Support System (SDSS) relating
to land degradation. This will enable informed debate and provide
a means for politicians to justify fund allocation at national and regional
scales without the need for a deep understanding of the science involved.
5. Conclusions
The paper has outlined how to construct a SPS capable of providing broad
brush land use forecasts for 2023 and 2048 that reflect data and modelling
results provided by several of the Medalus project teams. It attempts
to embody the essence of what might be styled a GIS approach. Almost
by definition GIS is a visual technology that uses maps which are generalised
to varying degrees to present results and communicate findings. There
is nothing wrong in creating visual presentations, indeed, it is a very
useful communications device even if the uncertainties and fuzzyness tends
to be hidden in the crisp map displays.
However, it is important not to overlook the deficiencies. To
be frank the results are broad brush and can be criticised on the following
grounds:
the market mechanisms and agricultural subsidy levels which may well link
(somehow) environmental change to the socio-economics to produce a land-use
response are implicit rather than explicit and assume a continuation of
the present;
the neural net model results could be improved if better quality climatic
and environmental data were available;
the uncertainty in the outputs has not yet been made explicit;
there is a mixture of inputs with very different levels of data uncertainty
and forecast reliability;
global climatic effects are equivalent to a shift in the boundaries of
agricultural capability;
it assumes technology remains more or less the same; and,
the land-use categorisation is very crude.
On the other hand, the SPS does have some good points, in particular:
it is the first attempt to predict 2023 and 2048 land-use changes linked
to forecast climatic change;
there is a linkage of physical - environmental and socio-economic aspects;
the same methodology has been consistently applied across the southern
EU;
it is a brave attempt to make broad brush land-use impact predictions for
50 years ahead;
it offers a different but useful approach to assessing the possible impacts
of climatic change on land-use by linking all the various components in
a novel and interesting way;
it has produced broad brush results relatively quickly which can be updated
as new and improved outputs from socio-economic and other environmental
models become available;
it is difficult to see how the challenge could be done in any better way
at present; and,
the results are understandable and should help focus the political debate
about how to handle these desertification problems by putting them into
a pan-EU context.
Of course the forecast predictions will be wrong! The hope is that
when aggregated to an appropriate level of geography they will not be so
wrong as to be useless. The aim is to raise awareness and to communicate
the possible impacts on land-use 50 years into the future. It is a straw
man! Let those who dislike these results demonstrate how with existing
science they can do better. It is also a challenge for those who
like the results, the onus being to improve them by reducing the uncertainties
in the inputs and enhancing the modelling that was used. There is
nothing in this paper that could not be improved either by the availability
of better data, improved forecasts, and more key variables; or by the input
of more effort to enhance the modelling. However, given current data, current
knowledge and current science it is difficult to see how we could do much
better. We wanted to create a need for land-use forecasting models
that incorporate climatic, environmental, and socio-economic variables.
We have chosen to meet this goal by outlining a practical system, however
imperfect. If the results outlined here are at all useful, then maybe the
resources needed to improve them will be forthcoming. Meanwhile we
would argue that our results are unique in that they are all that exists
right now so the principle of caveat emptor should be applied. The
results are the first of their kind and really only serve as a benchmark
and a preliminary test of methodology. All in all, the SPS appears
to provide a useful framework for assessing the possible impacts of climatic
change on land-use by linking all the various components in a novel and
interesting way.
Further details of the research can be found on the www at http://medalus.leeds.ac.uk/SEM/home.htm
Table
1. Advantages and disadvantages of neural networks
| Advantages |
Disadvantages |
| universal approximators |
computationally intensive |
| equation free |
may require long training times |
| highly non-linear |
choice of architecture is subjective |
| promise of good performance |
depends on training data |
| handle hard to model problems |
black box technology |
| automated |
conveys little knowledge |
Table
2. Variables used to create European population surfaces
| Digital Elevation Model 2 |
| Night time lights intensity at 1 km scale 3 |
| Distance from nearest built up areas 1 |
| Distance from nearest canal 1 |
| Distance from nearest international airport 1 |
| Distance from nearest national park 1 |
| Distance from nearest river 1 |
| Communications network density 1 |
| Motorway and dual carriageway road network density 1 |
| Main and minor road network density 1 |
| Railway network density 1 |
| Distance from extra large towns 1 |
| Distance from large towns 1 |
| Distance from medium sized towns 1 |
| Distance from small towns 1 |
| Location of built-up areas containing extra large town centres
1 |
| Location of built-up areas containing large town centres
1 |
| Location of built-up areas containing medium sized town
centres 1 |
| Location of built-up areas containing small town centres
1 |
| Location of named settlements and built-up areas 1 |
| Regiomap population density at NUTS-3 4 |
| Tobler's pycnophylactic population density based on NUTS-3
5 |
| RIVM's population density at 10 km scale 6 |
| Surpop Great Britain Census target population
density 7 |
Table
3. Variables used for predicting and forecasting agricultural land-use
| Variable Label and Data Source |
Description |
| Location of soil type 1 11 |
This includes the following soil
classes; cambisol, chernozem, luvisol, vertisol, plaggensols. |
| Location of soil type 2 11 |
This includes the following soil
classes; rendzina, gleysol, phaeozem, fluvisol, kastanozem, histozol, andosol. |
| Location of soil type 3 11 |
This includes the following soil
classes; arensol, ferralsol, ranker, planosol. |
| Location of soil type 4 11 |
This includes the following soil
classes; acrisol, podzoluvisol, greyzem, podzol, solonchak. |
| Location of soil type 5 11 |
This includes the following soil
classes; solonetz, xerosol. |
| Location of soil type 6 11 |
This includes the following soil
classes; lithosol, regosol, rock outcrops |
| Soil quality 11 |
Physical properties of the soil
were indexed in terms of their limitations or restrictions for agricultural
capability and combined to produce a crude measure of soil quality. |
| Potential biomass 10 |
Estimated potential biomass model
output at 30DM resolution. |
| Average temperature in Spring 9 |
Average monthly air temperature
in March, April and May. |
| Average temperature in Summer 9 |
Average monthly air temperature
in June, July and August. |
| Average temperature in Autumn 9 |
Average monthly air temperature
in September, October and November. |
| Average temperature in Winter 9 |
Average monthly air temperature
in December, January and February. |
| Average monthly precipitation in Spring
9 |
Average monthly precipitation
in March, April and May. |
| Average monthly precipitation in Summer9 |
Average monthly precipitation
in June, July and August. |
| Average monthly precipitation in Autumn9 |
Average monthly precipitation
in September, October and November. |
| Average monthly precipitation in Winter
9 |
Average monthly precipitation
in December, January and February. |
| Digital Elevation Model 12 |
Height above sea level. |
| Population |
1x10x10x1 Neural Network output. |
| Dominant agricultural land-use 11 |
The dominant agricultural land
use categorised into the following groups; arable, olive groves and orchards,
wasteland, and others. |
Appendix. Data sources
-
Bartholomews European 1DM dataset.
-
Digital Chart of the World.
-
The Defence Meteorological Satellite Program (DMSP) Operational Linescan
System (OLS) Night- time lights intensity dataset.
-
RegioMap (Eurostat) CD-ROM data.
-
Tobler's pycnophylactic (mass preserving) smooth interpolated population
density surface.
-
RIVM's raw population count for geographical regions.
-
UK Census data: Surpop 200 meter total population and population seeking
work surfaces of Great Britain; SAS Small Area Statistics.
-
Italian National Statistical Institute Registration total population count
point data.
-
CRU temperature and precipitation
data.
-
Biomass estimations from Medalus at Leeds.
-
Soils geographical database of Europe at scale 1:1,000,000 version 3.2.
-
GLOBE: Global Land One-KM Base Elevation Data version 0.1.
References
Burrough P, MacMillan R, van Deurson W (1992) Fuzzy Classification
Methods for Determining Land Suitability from Soil Profile Observation
and Topography. Journal of Soil Science, 43, 193-210.
Carpenter G, Gopal S, Martens S, Woodcock C (1997) Evaluation of Mixture
Estimation Methods for Vegetation Mapping. Boston University Center for
Adaptive Systems and Department of Cognitive and Neural Systems technical
report CAS/CNS-97-014.
Clarke J, Rhind D (1991) Population Data and Global Environmental Change.
International Social Science Council Programme on Human Dimensions of
Global Environmental Change, Working Group on Demographic Data.
Deichmann U, Eklundh L (1991) Global digital datasets for land degradation
studies: A GIS approach. United Nations Environment Programme, Global
Resource Information Database.
Deichmann U (1996) A Review of Spatial Population Database Design
and Modelling. United Nations Environment Programme, Global Resource
Information Database, and Consultative Group for International Agricultural
Research initiative on the Use of Geographic Information Systems in Agricultural
Research.
de Koning G, Veldkamp A, Verburg P, Kok K, Bergsma A (1997) CLUE:
A tool for spatially explicit and scale sensitive exploration of land use
changes. Working Paper, Wageningen Agricultural University, The Netherlands.
Elvidge C, Baugh K, Kihn E, Kroehl H, Davis E (1997) Mapping City Lights
With Nighttime Data From the DMSP Operational Linescan System. Photogrammetric
Engineering and Remote Sensing, 63, 727-734.
Elvidge C, Baugh K, Kihn E, Kroehl H, Davis E, Davis C (1997) Relation
between satelite observed visible-near infrared emissions, population,
economic activity and electric power consumption. International Journal
of Remote Sensing, 18 (6), 1373-1379.
FAO (Food and Agriclture Organisation), 1980, Natural resources and
the human environment for food and agriculture. Environment paper
No 1, Rome, Italy.
Goodchild M, Anselin L, Deichmann U (1993) A framework for the areal
interpolation of socio-economic data. Environment and Planning A,
25, 383-397.
Kosko B (1994) Fuzzy Thinking: The New Science of Fuzzy Logic.
Harper Collins.
McMahon M (1998) The home page of MEDALUS III: http://medalus.leeds.ac.uk/
McNeill D, Freiburger P (1994) Fuzzy Logic: The Discovery of a Revolutionary
Computer Technology. Simon and Schuster.
Moody A, Gopal S, Strahler A (1996) Artificial Neural Network Response
to Mixed Pixels in Coarse-Resolution Satellite Data. Remote Sensing
Environment 58, 329-343.
Openshaw S, Turner A (1998) The home page of MEDALUS III project 9.1:
GIS based socio-economic modelling: http://medalus.leeds.ac.uk/SEM/home.htm
Openshaw S, Perree T (1997) Methods for an intelligent continuous surface
transformation of socio-economic data for Europe. Extended Abstract for
1st International Conference on Geocomputation, September 1997,
Leeds, England.
Openshaw S, Openshaw C (1997) Artificial Intelligence in Geography.
Wiley & son.
Palutikof J, Agnew M (1997) Statistical Downscaling of Model Data. MEDALUS
III report from the Climatic Research Unit at the University of East
Anglia.
Ross T (1995) Fuzzy Logic with Engineering Applications. McGraw-Hill.
Sweitzer J, Langaas S (1994) Modelling population density in the
Baltic States using the Digital Chart of the World and other small scale
data sets. Technical Paper, Beiher International Institute of Ecological
Economics, Stockholm.
Tobler W (1979) Smooth Pycnophylactic Interpolation for Geographical
Regions. Journal of the American Statistical Association, 74, 519-529
Tobler W, Deichmann U, Gottsegen J, Maloy K (1995) The Global Demography
Project. NCGIA Technical Report TR-95-6.
Turner B, Moss R, Skole D (1993) Relating land use and global land-cover
change: A proposal for an IGBP-HDP core project. Report from the IGBP-HDP
Working Group on Land-Use/Land-Cover Change. Joint publication of the International
Geosphere-Biosphere Programme (Report No. 24) and the Human Dimensions
of Global Environmental Change Programme (Report No. 5). Stockholm:
Royal Academy of Sciences.
van Veidhuizen J, van de Veide R, van Woerden J (1995) Population mapping
to Support Environmental Monitoring: Some Experiences at European Scale.
Proceedings of the Joint European Conference and Exhibition on Geographic
Information, March 1995, The Hague, Netherlands.
Veldkamp A, Fresco L (1996) CLUE: a conceptual model to study the Conversion
of Land Use and its Effects. Ecological Modelling, 85, 253-270.
Veldkamp A, Fresco L (1997) Exploring Land Use Scenarios, An Alternative
Approach Based on Actual Land Use. Agricultural systems, 55(1),
1-17.
Verburg P, de Koning G, Kok K, Veldkamp A, Fresco L, Bouma J (1997)
Quantifying the spatial structure of landuse change: an integrated approach.
ITC Journal Special Issue: Geo-Information for Sustainable Land Management.
Warren A, Agnew C (1988) An assessment of desertification and land in
arid and semi-arid areas. International Institute for Environment and
Development (Paper No. 2), London: Ecology and Conservation Unit, University
College.
-
Figure
1. Basic outline of the Synoptic Preiction System
-
-
-
Figure
2. Structure of the Synoptic Prediction System
-
-
-
Figure
3. A map of EU Population at a 1DM resolution
-
-
-
-
Figure 4. Temperature maps
-
Present day
-
-
Forecast for 2048
-
-

Change
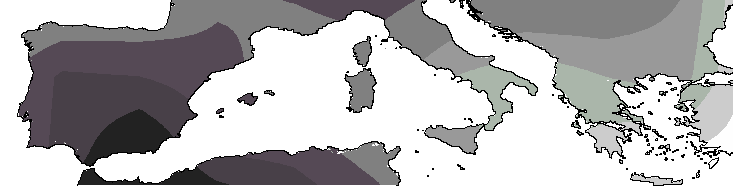
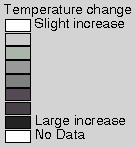
Figure 5. Precipitation maps
Present day
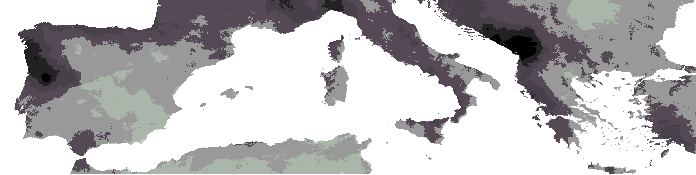
Forecast for 2048
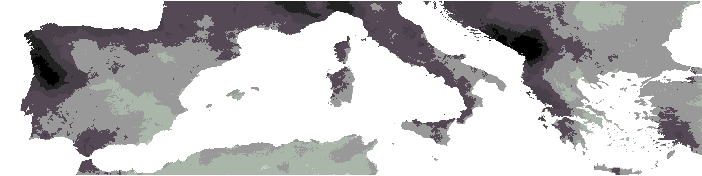

Change

Figure
6. Observed, predicted and forecast dominant arable landuse
Observed
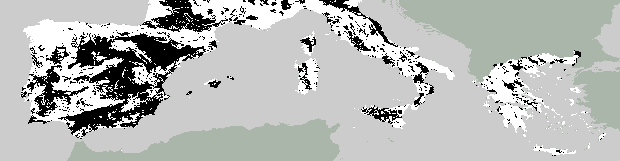
Predicted
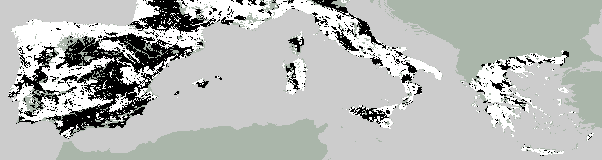
Forecast
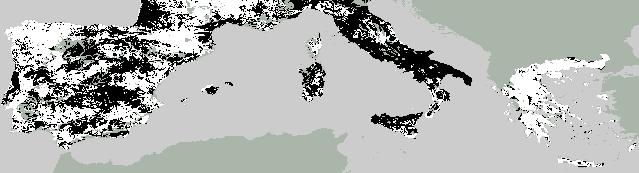
Figure
7. Observed, predicted and forecast dominant tree landuse
Observed
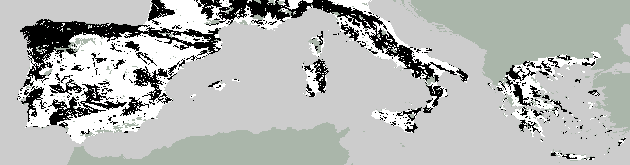
Predicted
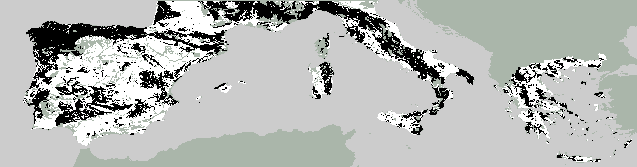
Forecast
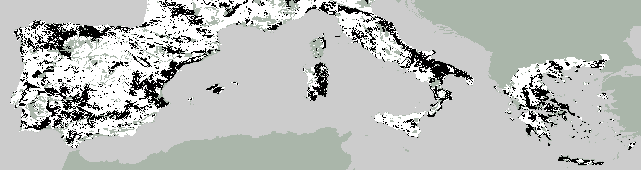
Figure
8. Observed, predicted and forecast dominant wasteland
Observed
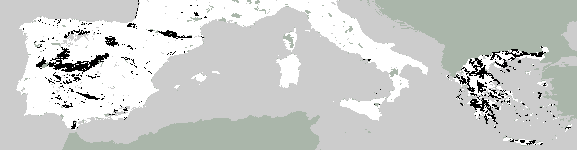
Predicted
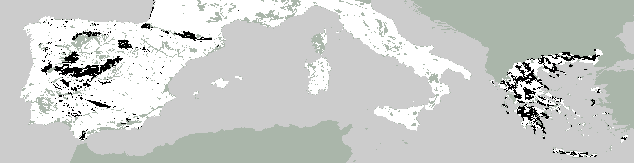
Forecast